



Summary
In this article, we are going to provide you with a set of tools, that will allow you to analyze restaurants in your neighbourhood and use that information to your advantage. Even though it may seem this is only for individuals who may be interested in seeking popular dishes, it also provides valuable information for businesses about their competition as well as insights into their own dining services.
If you want to try the code directly from our notebook, just download it from the repository.
To achieve this, we are going to utilize CLIP, which is a very capable model as it can project many different kinds of modalities into a common vector space. In case you would be interested in a introduction to this transformer-based model and the other technologies we utilize in our guide, you could also follow our official documentation for image similarity search and vector store in langchain. Since our data will consist of reviews from Google Maps, we will focus only on textual and image modalities. This is especially powerful in combination with Deep Lake, which is a Database for AI capable of efficient storage of both of these. In particular, we will use it for vector search, in which we will extract image and text reviews that are the most relevant for a particular task.
Additionally, to further enhance our capabilities, we employed LangGraph, a library for building stateful, multi-actor applications with LLMs, built on top of LangChain.
Overall, this will allow you to extract information from publicly available reviews and utilize it for further decision-making. Be it finding an unexplored place or understanding what tastes people around share.
Steps
- Selecting Location
- Scraping the Restaurant Reviews
- Ingesting the data into Deep Lake Vector Store
- Finding the Best Reviewed Restaurant with Your Favourite Food
- Question Answering Based on Reviews
- Categorizing Images to Restaurant Tags
- Clustering All Images to Find the Most Popular Dishes
- Interacting with LangGraph
- Summarizing the Findings
1!pip install openai langchain deeplake apify-client torch open_clip_torch deeplake langchain_openai langgraph
2
1# Import libraries
2from apify_client import ApifyClient
3import urllib.request
4from langchain.vectorstores import DeepLake
5from langchain.chains import RetrievalQA
6from langchain.chat_models import ChatOpenAI
7from langchain.llms import OpenAI
8from langchain import PromptTemplate
9from langchain.embeddings.base import Embeddings
10import sys
11
12import torch
13import os
14import re
15from tqdm import tqdm
16from collections import defaultdict
17from PIL import Image
18import pandas as pd
19import numpy as np
20import base64
21from io import BytesIO
22from IPython.display import HTML
23from sklearn.cluster import KMeans
24
25pd.set_option('display.max_colwidth', None)
26
27activeloop_token='YOUR_ACTIVELOOP_TOKEN'
28os.environ['ACTIVELOOP_TOKEN'] = activeloop_token
29
30os.environ['OPENAI_API_KEY'] = '<YOUR_OPENAI_TOKEN>'
31os.environ['ACTIVELOOP_TOKEN'] = '<YOUR_ACTIVELOOP_TOKEN>'
32os.environ['APIFY_API_TOKEN'] = '<YOUR_APIFY_API_TOKEN>'
33
34os.environ['TAVILY_API_KEY'] = "<YOUR_TAVILY_API_TOKEN>"
35
Step 1: Selecting Location
First of all, you need to find the longitude and latitude of your location, from which the data will be scraped. This can be done in many ways, but the most straightforward is to open Google Maps, search for the place, right-click it and copy the coordinates. In our example, we will use the following location: Crepevine, 300 Castro Street, Mountain View, CA 94041, United States of America, which gives us Latitude=37.3926 and Longitude=-122.0800. In case you would need to automate this, feel free to use geocoding via Google Maps API.
Step 2: Scraping the Restaurant Reviews
Google Maps API offers many capabilities including information about places from a given location. They also have a generous free budget of 300$ every month, but it was a great disappointment that it is only able to extract 5 reviews for each restaurant, which is far from being enough for our task. Therefore, we recommend to utilize Apify actor. We experimented with other scrapers too, but unless you are willing to pay extra for faster scraping, it should be sufficient. You can see the run_inputs for more details, but this is the summary of our setup:
- all restaurants in 2 KM radius
- reviews only from 1.1.2022
- no limit for max images/texts/restaurants
Apify provides a budget of 5$ per month and to give you an idea, here are the results of our run:
- total restaurants scraped: 130
- total scraping time: 75 minutes
- total costs: 2.3$
This should be fast enough to scrape restaurants in your city, however, expanding to more locations might be problematic.
1# Initialize the ApifyClient with your API token
2client = ApifyClient(os.environ["APIFY_API_TOKEN"])
3
4# Prepare the Actor input
5run_input = {
6 "customGeolocation": {
7 "type": "Point",
8 "coordinates": [
9 "-122.0800081",
10 "37.39252210000001"
11 ],
12 "radiusKm": 2
13 },
14 "deeperCityScrape": False,
15 "includeWebResults": False,
16 "language": "en",
17 "maxCrawledPlacesPerSearch": 500,
18 "maxImages": 200,
19 "maxReviews": 200,
20 "oneReviewPerRow": False,
21 "onlyDataFromSearchPage": False,
22 "reviewsSort": "newest",
23 "reviewsStartDate": "2022-01-01",
24 "scrapeResponseFromOwnerText": False,
25 "scrapeReviewId": False,
26 "scrapeReviewUrl": False,
27 "scrapeReviewerId": False,
28 "scrapeReviewerName": False,
29 "scrapeReviewerUrl": False,
30 "searchStringsArray": [
31 "restaurant"
32 ]
33}
34
35# Run the Actor and wait for it to finish
36run = client.actor("compass/crawler-google-places").call(run_input=run_input)
37
You can now proceed with the returned results or download them from your Apify account in csv format
1choose = ''
2if choose == 'csv':
3 scraped_data = pd.read_csv("items.csv")
4 scraped_data = scraped_data.to_dict()
5else:
6 scraped_data = client.dataset(run['defaultDatasetId']).list_items().items
7
After we scrape the data, it is necessary to define a function to extract reviews and other parameters. Since the scraper only extracts the URL link, it is useful to save the images during the first run and save them locally. This is useful because during our experiments we encountered problems when some of the images were no longer available and we needed to check each URL separately prior to ingesting the data into Deep Lake. Their format was different from other images which caused issues during ingestion. Nevertheless, it is likely that there is a more efficient way to avoid it.
The image requesting is quite slow as well and in our experiments it took around 70 minutes to process the total of 7813 images.
1def review_mapping_function(item, save_images=False):
2 title = item["title"]
3 text_dict = defaultdict(list)
4 image_dict = defaultdict(list)
5 tag_dict = defaultdict(list)
6 image_folder = "images/" + title
7 image_folder = image_folder.replace('|', '')
8 if (not os.path.exists(image_folder)) and save_images:
9 os.makedirs(image_folder)
10
11 for tag in item['reviewsTags']:
12 tag_dict['metadata'] += [{'title': title}]
13 tag_dict['tags'] += [tag['title']]
14 for tag in ['interior', 'menu', 'drink']:
15 tag_dict['metadata'] += [{'title': title}]
16 tag_dict['tags'] += [tag]
17
18 for idx, r in enumerate(item["reviews"]):
19 text = r["textTranslated"]
20 # if text was originally in english, textTranslated is None
21 if text is None:
22 text = r["text"]
23 image = r["reviewImageUrls"]
24
25 if text:
26 metadata = {
27 "title": title,
28 "review_id": idx,
29 "likes": r['likesCount'],
30 "stars": r['stars'],
31 }
32 text_dict["text"].append(text)
33 text_dict["metadata"].append(metadata)
34
35 if image:
36 j=0
37 for image_url in image:
38 image_path = f"{image_folder}/{j}.jpg"
39 metadata = {
40 "title": title,
41 "review_id": idx,
42 "likes": r['likesCount'],
43 "stars": r['stars'],
44 }
45 image_dict["metadata"].append(metadata)
46 # change image size
47 image_url = re.sub('=w[0-9]+-h[0-9]+-', '=w512-h512-', image_url)
48 if save_images:
49 urllib.request.urlretrieve(image_url, image_path)
50
51 if os.path.isfile(image_path):
52 # image was saved, we can just load it with path
53 image_dict["image"].append(image_path)
54 j+=1
55 else:
56 # image not saved, need to put url and request it later
57 image_dict["image"].append(image_url)
58
59 return {'text_dict': text_dict, 'image_dict': image_dict, 'tag_dict': tag_dict}
60
1reviews = [review_mapping_function(item) for item in scraped_data]
2
1# extract reviews
2reviews = [review_mapping_function(item) for item in client.dataset(run["defaultDatasetId"]).iterate_items()]
3
4# aggregate them into a single dictionary
5text_dict_concat = defaultdict(list)
6image_dict_concat = defaultdict(list)
7tag_dict_concat = defaultdict(list)
8
9for r in reviews:
10 for key in r['text_dict'].keys():
11 text_dict_concat[key] += r['text_dict'][key]
12 for key in r['image_dict'].keys():
13 image_dict_concat[key] += r['image_dict'][key]
14 for key in r['tag_dict'].keys():
15 tag_dict_concat[key] += r['tag_dict'][key]
16
3) Ingesting the Data into Deep Lake Vector Store
Initially, we experimented with various setups of the vector database. Even though the Deep Lake is capable of saving text and image tensors in the same database, it gets quite complex as one review can have none or a single textual message, while images can range from zero up to as many as the reviewers add. If we decide to put all of them in the same database, it might look convenient but we end up duplicating the textual messages. As we did not find a particular use case that would benefit from this and it only resulted in a more complicated similarity search, we created two separate databases. One storing images from reviews and the other textual reviews, each with a different call to our custom embedding function. Additionally, we also introduced a third Deep Lake Vector Store with tags from each restaurant, which will be particularly useful during categorization in step 6.
Also note that before ingesting the data, it is a common practice to split the text into documents. However, as Google map reviews are limited to 4096 characters (around 700 words), it is not necessary.
1activeloop_ord_id = 'YOUR_ACTIVELOOP_ORG'
2
1from deeplake import VectorStore
2
3overwrite = False
4
5# Create empty database for texts
6reviews_path_texts = f'hub://{activeloop_ord_id}/reviews-texts'
7reviews_texts = VectorStore(
8 path = reviews_path_texts,
9 tensor_params = [
10 {'name': 'text', 'htype': 'text'},
11 {'name': 'embedding', 'htype': 'embedding'},
12 {'name': 'metadata', 'htype': 'json'}
13 ],
14 overwrite = overwrite
15)
16# Create empty database for images
17reviews_path_images = f'hub://{activeloop_ord_id}/reviews-images'
18reviews_images = VectorStore(
19 path = reviews_path_images,
20 tensor_params = [
21 {'name': 'image', 'htype': 'image', 'sample_compression': 'png'},
22 {'name': 'embedding', 'htype': 'embedding'},
23 {'name': 'metadata', 'htype': 'json'}
24 ],
25 overwrite = overwrite
26)
27# Create empty database for tags
28reviews_path_tags = f'hub://{activeloop_ord_id}/restaurants-tags'
29restaurants_tags = VectorStore(
30 path = reviews_path_tags,
31 tensor_params = [
32 {'name': 'tag', 'htype': 'text'},
33 {'name': 'embedding', 'htype': 'embedding'},
34 {'name': 'metadata', 'htype': 'json'}
35 ],
36 overwrite = overwrite
37)
38
Now, let’s define the custom OpenCLIP embedding function, which is a wrapper around CLIP. Since the model needs to explicitly set the modality of input, it has two call options: 1) for text embedding and 2) for image embedding. It is quite important to set up CUDA and run the predictions on GPU, as the performance on the CPU is quite slow.
1from typing import Any, Dict, List
2
3from langchain.pydantic_v1 import BaseModel, root_validator
4from langchain.schema.embeddings import Embeddings
5from PIL import Image
6import requests
7from io import BytesIO
8
9class OpenCLIPEmbeddings(BaseModel, Embeddings):
10 model: Any
11 preprocess: Any
12 tokenizer: Any
13 # Select model: https://github.com/mlfoundations/open_clip
14 model_name: str = "ViT-H-14"
15 checkpoint: str = "laion2b_s32b_b79k"
16
17 @root_validator()
18 def validate_environment(cls, values: Dict) -> Dict:
19 """Validate that open_clip and torch libraries are installed."""
20 try:
21 import open_clip
22
23 # Fall back to class defaults if not provided
24 model_name = values.get("model_name", cls.__fields__["model_name"].default)
25 checkpoint = values.get("checkpoint", cls.__fields__["checkpoint"].default)
26
27 # Load model
28 model, _, preprocess = open_clip.create_model_and_transforms(
29 model_name=model_name, pretrained=checkpoint
30 )
31 tokenizer = open_clip.get_tokenizer(model_name)
32 values["model"] = model
33 values["preprocess"] = preprocess
34 values["tokenizer"] = tokenizer
35
36 except ImportError:
37 raise ImportError(
38 "Please ensure both open_clip and torch libraries are installed. "
39 "pip install open_clip_torch torch"
40 )
41 return values
42
43 def embed_documents(self, texts: List[str]) -> List[List[float]]:
44 text_features = []
45
46 self.model.to('cuda')
47
48 tokenized_text = self.tokenizer(texts)
49 # for text in texts:
50 # # Tokenize the text
51 # tokenized_text = self.tokenizer(text)
52
53 with torch.no_grad(), torch.cuda.amp.autocast():
54 # Encode the text to get the embeddings
55 embeddings_tensor = self.model.encode_text(tokenized_text.to('cuda'))
56
57 # Normalize the embeddings
58 norm = embeddings_tensor.norm(p=2, dim=1, keepdim=True)
59 normalized_embeddings_tensor = embeddings_tensor.div(norm)
60
61 # Convert normalized tensor to list and add to the text_features list
62 embeddings_list = normalized_embeddings_tensor.squeeze(0).tolist()
63 text_features.append(embeddings_list)
64
65 return text_features
66
1
2 def embed_query(self, text: str) -> List[float]:
3 return self.embed_documents([text])[0]
4
5 def embed_image(self, uri: str) -> List[float]:
6 return self.embed_images([uri])[0]
7
8 def embed_images(self, uris: List[str]) -> List[List[float]]:
9
10 try:
11 from PIL import Image as _PILImage
12 except ImportError:
13 raise ImportError("Please install the PIL library: pip install pillow")
14
15 # Open images directly as PIL images
16 pil_images = []
17 for uri in uris:
18 pil_images.append(Image.open(uri))
19
20 self.model.to('cuda')
21
22 # Preprocess the image for the model
23 preprocessed_image = [self.preprocess(pil_image) for pil_image in pil_images]
24
25 with torch.no_grad(), torch.cuda.amp.autocast():
26 # Encode the image to get the embeddings
27 embeddings_tensor = self.model.encode_image(torch.stack(preprocessed_image).to('cuda'))
28
29 # Normalize the embeddings tensor
30 norm = embeddings_tensor.norm(p=2, dim=1, keepdim=True)
31 normalized_embeddings_tensor = embeddings_tensor.div(norm)
32
33 # Convert tensor to list and add to the image_features list
34 embeddings_list = normalized_embeddings_tensor.squeeze(0).tolist()
35
36 return embeddings_list
37
38
Here, we proceed to ingest the scraped data into Deep Lake. Note that it is important to set ingestion_batch_size appropriately for your GPU capacity, to avoid running out of memory during embedding prediction.
1# loading the model
2clip = OpenCLIPEmbeddings(model_name="ViT-g-14", checkpoint="laion2b_s34b_b88k")
3
4
1import requests
2from PIL import Image
3from io import BytesIO
4
5def save_image_from_url(url, restaurant_idx):
6 # Download the image
7 if not os.path.exists("images"):
8 os.mkdir("images")
9
10 response = requests.get(url)
11 image = Image.open(BytesIO(response.content))
12 path_image = f"images/{restaurant_idx}.png"
13 image.save(path_image, 'PNG')
14 return path_image
15
16
1from tqdm import tqdm
2
3all_image_urls=image_dict_concat['image']
4path_images = []
5for image_idx, image_url in tqdm(enumerate(all_image_urls), total=len(all_image_urls)):
6 try:
7 path_images.append(save_image_from_url(image_url, image_idx))
8 except Exception:
9 continue
10
11
1# texts
2reviews_texts.add(
3 text = text_dict_concat['text'],
4 metadata = text_dict_concat['metadata'],
5 embedding_function = clip.embed_documents,
6 embedding_data = text_dict_concat['text'],
7 embedding_tensor="embedding",
8)
9# images
10reviews_images.add(
11 image = path_images,
12 metadata = image_dict_concat['metadata'],
13 embedding_function = clip.embed_images,
14 embedding_data = path_images,
15 embedding_tensor="embedding",
16)
17# tags
18restaurants_tags.add(
19 tag = tag_dict_concat['tags'],
20 metadata = tag_dict_concat['metadata'],
21 embedding_function = clip.embed_documents,
22 embedding_data = tag_dict_concat['tags'],
23 embedding_tensor="embedding",
24)
25
In the case of 9607 textual reviews this took around 30 minutes, in the case of 7813 images this was around 1.5 hours and for tags it was under 5 minutes. This Was given mostly by the long inference time of the OpenCLIP model.
4) Finding the Best Reviewed Restaurant with Your Favourite Food
Finally, it’s time to get some useful insights into our embedded dataset! We start by finding the 200 most relevant texts and images for search input burger.
1search = 'burger'
2
3text_search_results = reviews_texts.search(
4 embedding_data = [search],
5 embedding_function = clip.embed_documents,
6 k=200,
7)
8image_search_results = reviews_images.search(
9 embedding_data = [search],
10 embedding_function = clip.embed_documents,
11 k=200,
12)
13
Another way to get results from deep lake is via TQL. It stands for Total Quality Logistics, which is a third-party logistics provider that connects shippers with carriers to move freight. They offer services such as truckload, LTL (less than truckload), intermodal, and supply chain solutions. TQL is one of the largest freight brokerage firms in the United States.
1query_emb = clip.embed_documents([search])
2query_emb_str = "ARRAY["+",".join([f"{emb}" for emb in query_emb[0]])+"]"
3info_to_scrape = 10
4tql_images = f"select image, metadata, id, score from (select *, cosine_similarity(embedding, {query_emb_str}) as score where cosine_similarity(embedding, {query_emb_str}) > 0.2 order by metadata['rating'] desc limit {info_to_scrape})"
5tql_reviews = f"select metadata, id, score from (select *, cosine_similarity(embedding, {query_emb_str}) as score where cosine_similarity(embedding, {query_emb_str}) > 0.2 order by metadata['rating'] desc limit {info_to_scrape})"
6
7image_search_results_tql = reviews_images.search(query=tql_images)
8text_search_results_tql = reviews_texts.search(query=tql_reviews)
9
10
Now we can aggregate the results
1# aggregating the results
2results = defaultdict(lambda: defaultdict(list))
3
4for md, img, id in zip(image_search_results['metadata'], image_search_results['image'],image_search_results['id']):
5 results[md['title']]['images'].append(img)
6 results[md['title']]['image_likes'].append(md['likes'])
7 results[md['title']]['image_stars'].append(md['stars'])
8 results[md['title']]['image_review_ids'].append(md['review_id'])
9 results[md['title']]['image_ids'].append(id)
10
11for md, txt in zip(text_search_results['metadata'], text_search_results['text']):
12 results[md['title']]['texts'].append(txt)
13 results[md['title']]['text_likes'].append(md['likes'])
14 results[md['title']]['text_stars'].append(md['stars'])
15 results[md['title']]['text_review_ids'].append(md['review_id'])
16
Now let’s summarize the text reviews. For this, we will use a simple prompt template that extracts a summary of keywords from a list of reviews and also includes an example. Since the reviews are typically short messages, we can only concatenate each set together and do not need to chain the calls with tools that are offered by LangChain. If you’re interested in delving deeper into LangChain and exploring its capabilities further, we invite you to explore our comprehensive guide available at this link.
1llm = OpenAI(model_name='gpt-3.5-turbo-instruct', temperature=0.5)
2
3prompt_template = """You are provided with a list of {search} reviews. Summarize what customers write about it:
4
5Example:
6List of {search} reviews:
7Great spicy Burger !\nThe burger is solid and delicious. Just be aware that it's high in calories (1100 calories!).\nVery good food, I would recommend to the burger lovers out there.\nThe burgers here are pretty solid\nthey also have a rotating beer top which has some good variety\nFantastic food\nBest Burgers In Town!!!\nGreat food\nDELICIOUS! BISON BURGER IS THE BEST"
8delicious, cheap, good atmosphere, quick service, many options in menu.
9
10Keyword summary of the {search} reviews:
11Spicy burger, Solid and delicious, Recommended for burger lovers, Good variety of beers, Fantastic food, Best burgers in town, Bison burger is delicious
12
13List of {search} reviews:
14{reviews}
15
16Keyword summary of the {search} reviews:
17"""
18
To put it all together, we are going to loop through all of the 200 texts and 200 images that have the most similar embedding to burger, group them by restaurant title and define the following:
avg_txt_stars- average stars on text messages for a given restaurantn_texts- number of text messages for a given restauranttext_summary- keyword summary based on all of the text messages for a given restaurantavg_img_stars- average stars on images for a given restaurantn_images- number of images for a given restaurantimg_in_text_perc- percentage number of images selected along with their original text message (% of images connected with text by thereview_id)image_{i}- image in top n most similar images
To make the table more clear, we subset only the top 5 images (sorted by the similarity score) and the top 5 restaurants (sorted by the number of images)
1from langchain.vectorstores import DeepLake
2
3reviews_images_lc = DeepLake(
4 dataset_path = reviews_path_images,
5)
6
7reviews_texts_lc = DeepLake(
8 dataset_path = reviews_path_texts,
9)
10
11restaurants_tags_lc = DeepLake(
12 dataset_path = reviews_path_tags,
13)
14
1df_1 = pd.DataFrame(columns=['title','info', 'text_summary'])
2top_n = 5 # maximum number of images for each restaurant
3n_restaurants = 5
4const = 1
5
6i = 0
7visualizer_images = []
8for title, values in results.items():
9 df_1.loc[i, 'title'] = title
10
11 info = {}
12
13 if len(values['texts']) > 0:
14 weights = np.add(values['text_likes'], const)
15 avg_txt_stars = round(np.average(values['text_stars'], weights=weights), 2)
16 info['avg_txt_stars'] = avg_txt_stars
17 n_texts = len(values['text_stars'])
18 info['n_texts'] = n_texts
19
20 # set the prompt template
21 PROMPT = PromptTemplate(
22 template=prompt_template,
23 input_variables=["reviews"],
24 partial_variables={"search": search},
25 )
26 reviews = "\n".join(values['texts'])
27 review_summary = llm(PROMPT.format(reviews=reviews, search=search))
28 df_1.loc[i, 'text_summary'] = review_summary
29
30 if len(values['images']) > 0:
31 weights = np.add(values['image_likes'], const)
32 avg_img_stars = round(np.average(values['image_stars'], weights=weights), 2)
33 info['avg_img_stars'] = avg_img_stars
34 n_images = len(values['image_stars'])
35 info['n_images'] = n_images
36 df_1.loc[i, 'n_images'] = n_images
37 visualizer_images += values['image_ids']
38
39 images_in_text = sum([i in values['text_review_ids'] for i in values['image_review_ids']])
40 img_in_text_perc = round(images_in_text / len(values['image_review_ids']) * 100, 2)
41 info['img_in_text_perc'] = img_in_text_perc
42 sorted_images = [x for _, x in sorted(zip(values['image_likes'], values['images']), reverse=True, key=lambda x: x[0])]
43 for j, img in enumerate(sorted_images):
44 if j < top_n:
45 df_1.loc[i, f'image_{j+1}'] = Image.fromarray(img).convert('RGB')
46
47 df_1.loc[i, 'info'] = str(info)
48
49 i+=1
50
51
For better visualisation, we also define HTML formatters as inspired by this notebook and render the HTML as generated by pandas.
1def get_thumbnail(path):
2 i = Image.open(path)
3 i.thumbnail((150, 150), Image.LANCZOS)
4 return i
5
6def image_base64(im):
7 if isinstance(im, str):
8 im = get_thumbnail(im)
9 with BytesIO() as buffer:
10 im.save(buffer, 'jpeg')
11 return base64.b64encode(buffer.getvalue()).decode()
12
13def image_formatter(im):
14 return f'<img src="data:image/jpeg;base64,{image_base64(im)}">'
15
16def bullet_formatter(text):
17 text = eval(text)
18 l = '<div> <ul style="text-align: left;">'
19 for key, value in text.items():
20 l += f"\n <li>{key}: {value}</li>"
21 l += "\n</ul></div>"
22 return l
23
24
1# sort by n_images
2df_1 = df_1.sort_values(by=['n_images'], ascending=False).drop(['n_images'],axis=1)
3# render HTML
4formatters = [None, bullet_formatter, None] + [image_formatter] * top_n
5HTML(df_1[:n_restaurants].to_html(formatters=formatters, escape=False, col_space=[150]*df_1.shape[1]))
6

The image results as you can see are very accurate, especially when you sort by vector similarity score. Summarizing textual reviews may seem to be sufficient too, but there’s plenty of room for prompt engineering. Also, note that img_in_text_perc is very low and it was more of an experiment rather than proof that the results make sense. In other words, it is difficult to filter the images and text from the same review based on one embedding (in our example from burger).
Deep Lake Visualization Engine
Deep Lake visualization engine allows users to interact with and visualize data stored in their databases. It provides a user-friendly interface for exploring and understanding the data, making it easier for researchers and developers to work with large datasets effectively.
For a detailed understanding of Deep Lake visualization engine and how it enhances your ability to comprehend the relationships between tensors within a dataset, we encourage you to visit our technical documentation at this link.
If your dataset is not public you must also pass the private token in the request as follow:
iframe_url = f"https://app.activeloop.ai/visualizer/iframe?url={reviews_path_images}&token=<YOUR_ACTIVELOOP_TOKEN>&query=
1def activeloop_visualizer(result:dict=None, list_images_id:list[str] = None):
2 iframe_html = '<iframe src={url} width="570px" height="400px"/iframe>'
3
4 if result is not None:
5 images_id = [el for el in result['id']]
6 elif list_images_id is not None:
7 images_id = list_images_id
8 else:
9 raise Exception("specify the images ids")
10
11 images_id = str(images_id).strip("[]")
12 query = f"select image where id in ({images_id})"
13 if activeloop_token is not None:
14 iframe_url = f"https://app.activeloop.ai/visualizer/iframe?url={reviews_path_images}&token={activeloop_token}&query="
15 else:
16 iframe_url = f"https://app.activeloop.ai/visualizer/iframe?url={reviews_path_images}&query="
17
18 urls = [iframe_url + urllib.parse.quote(query)]
19 html = iframe_html.format(url=urls[0])
20 return HTML(html)
21
1activeloop_visualizer(list_images_id=visualizer_images)
2
5) Question Answering Based on Reviews
Of course, there are many use cases for LangChain as well. In particular, you could utilize the text reviews as a custom document to answer any question. Note that as we embedded the tensors by OpenCLIP, we also need to set this function in the retriever. Also, as answering questions from the whole data does not make much sense in this case, we selected a single restaurant via the filter option in search_kwargs.
1retriever = reviews_texts_lc.as_retriever(
2 search_type = "similarity",
3 search_kwargs = {
4 "k": 20,
5 "embedding_function": clip.embed_documents,
6 "filter": {'metadata': {'title': 'Taqueria La Espuela'}}
7 }
8)
9
To see what reviews based on similarity search are provided to the LLM model to answer your question, we can inspect the relevant_documents as seen in the 5 examples below.
1query = 'What customers like about the restaurant?'
2relevant_docs = retriever.get_relevant_documents([query])
3relevant_docs[0:5]
4
Now, let’s define the QA retrieval and run your questions. But again, we stress the importance of further improvements of the prompt templates as they have significant effect on the results.
1qa = RetrievalQA.from_llm(llm, retriever=retriever)
2qa.run([query])
3
1query = 'What would customers improve about this restaurant?'
2qa.run([query])
3
6) Categorizing Images to Restaurant Tags
Typically, if your task is to categorize images, you need to train a model on a labelled set, which then limits the capabilities as it can predict only classes included in the training data. Here, however, we try to achieve similar results without training or finetuning any categorization model at all. Of course, the model isn’t perfect, but the results seem to be pretty cool considering that we did not perform any finetuning on restaurant data and it is just the original OpenCLIP.
Again, we filter only a single restaurant to make the predictions more clear.
1tensors = reviews_images_lc.vectorstore.search(
2 return_tensors = ['image','embedding','id'],
3 filter = {'metadata': {'title':'Taqueria La Espuela'}},
4)
5
Finally, we are going to utilize the third Deep Lake Vector Store which stores the restaurant tags along with their embeddings. The categorization is pretty straightforward as we are searching for the closest tag embedding for each of our images from the selected restaurant. After that, we sort them by similarity scores and display the top 10 images for each category.
Notice that for practical reasons we also included additional tags interior, menu and drink for each restaurant as these were quite frequent images not included in the tags.
1df_2 = pd.DataFrame()
2i_dict = defaultdict(lambda: 1)
3n_images = 200
4max_cols = 10
5categories = []
6scores = []
7
8for embedding in tensors['embedding']:
9 closest = restaurants_tags_lc.vectorstore.search(
10 embedding = embedding,
11 k = 1,
12 filter = {'metadata': {'title':'Taqueria La Espuela'}},
13 )
14 categories += [closest['tag'][0]]
15 scores += [closest['score']]
16
17sorted_images = [x for _, x in sorted(zip(scores, tensors['image']), reverse=True)]
18sorted_categories = [x for _, x in sorted(zip(scores, categories), reverse=True)]
19
20n = 0
21for category, img in zip(sorted_categories, sorted_images):
22 if n < n_images:
23 i = i_dict[category]
24 df_2.loc[category, f'image_{i}'] = Image.fromarray(img).convert('RGB')
25 i_dict[category]+=1
26 n+=1
27
Again, rendering the formatted HTML.
1formatters = [image_formatter] * min(max_cols, df_2.shape[1])
2HTML(df_2.iloc[:,:max_cols].to_html(formatters=formatters, escape=False))
3

We can visualize the images in our Activeloop dataset
1activeloop_visualizer(result=tensors)
2
7) Clustering All Images to Find the Most Popular Dishes
What if we want to group all of the images based on their similarity without any particular label to find the most popular meals? Of course, we can do that too! At the time of writing this article, Deep Lake, unfortunately, does not support computing the cluster groups and extracting them. Anyways, it is currently on a road map and meanwhile, you can visualise them in the Deep Lake UI that computes them on the fly or follow this guide that extracts the embeddings from Deep Lake Vector Store and calculates the clusters locally.
We start by taking out 5000 images whose embedding is similar to food. This process is quite time-consuming since we are also extracting the images with metadata information.
1tensors = reviews_images_lc.vectorstore.search(
2 return_tensors = ['metadata','image','embedding', 'id'],
3 embedding_data = ['food'],
4 embedding_function = clip.embed_documents,
5 k = 5000,
6)
7
Then simply run the K-means clustering algorithm from sklearn. The number of clusters here is arbitrary as clustering is an unsupervised algorithm so you can play with other parameters too.
1n_clusters = 5
2kmeans_model = KMeans(n_clusters = n_clusters)
3clusters = kmeans_model.fit_predict(tensors['embedding']).tolist()
4
We then create a simple data frame that aggregates information about clusters, stars and likes for each image and then select the top 10 images (sorted by similarity) from the top 5 clusters (sorted by average number of likes).
1agg = pd.DataFrame()
2df_3 = pd.DataFrame(columns=['cluster', 'avg_likes', 'n_images'])
3max_cols = 10
4max_rows = 5
5cluster_visualizer_images = []
6n = 0
7for cluster, img, md, image_ids in zip(clusters, tensors['image'], tensors['metadata'], tensors['id']):
8 agg.loc[n, 'cluster'] = cluster
9 agg.loc[n, 'stars'] = md['stars']
10 agg.loc[n, 'likes'] = md['likes']
11 agg.loc[n, 'image'] = Image.fromarray(img).convert('RGB')
12 agg.loc[n, 'image_ids'] = image_ids
13 n += 1
14
15agg = agg.sort_values(by=['likes'], ascending=False)
16agg = agg.groupby('cluster').agg({'likes':['mean','count'], 'image': list,'image_ids': list})
17agg = agg.sort_values(by=[('likes', 'mean')], ascending=False)
18
19r = 1
20for index, row in agg.iterrows():
21 if r <= max_rows:
22 df_3.loc[r, 'cluster'] = int(index)
23 df_3.loc[r, 'avg_likes'] = round(row['likes']['mean'], 2)
24 df_3.loc[r, 'n_images'] = row['likes']['count']
25 cluster_visualizer_images.append(row['image_ids'])
26
27 c=1
28 for img in row['image']['list']:
29 if c <= max_cols:
30 df_3.loc[r, f'image_{c}'] = img
31 c+=1
32 r+=1
33
34
And rendering it.
1formatters = [None, None, None] + [image_formatter] * max_cols
2HTML(df_3.to_html(formatters=formatters, escape=False))
3

As you can see, the food in each cluster is indeed quite similar. However, average likes might not be the appropriate metric to sort the most popular food as the number of likes on each image is typically low. If the cluster consists of many images, it is then more likely that we will not see it on top of this list.
It is possible to view the images of the different clusters directly on Activeloop by specifying the number of the cluster that interests us
1cluster_number = 0
2activeloop_visualizer(list_images_id=cluster_visualizer_images[cluster_number][0])
3
1cluster_number = 1
2activeloop_visualizer(list_images_id=cluster_visualizer_images[cluster_number][0])
3
Introduction to LangGraph
LangGraph extends the LangChain Expression Language with the ability to coordinate multiple chains, or actors, across multiple steps of computation in a cyclic manner, inspired by Pregel and Apache Beam. The main use is for adding cycles to your LLM application, crucial for agent-like behaviors, where you call an LLM in a loop, asking it what action to take next. Specifically, we utilized Agent Supervisor within LangGraph, acting as a coordinator to delegate tasks between independent agents, orchestrating interactions and workflows efficiently.
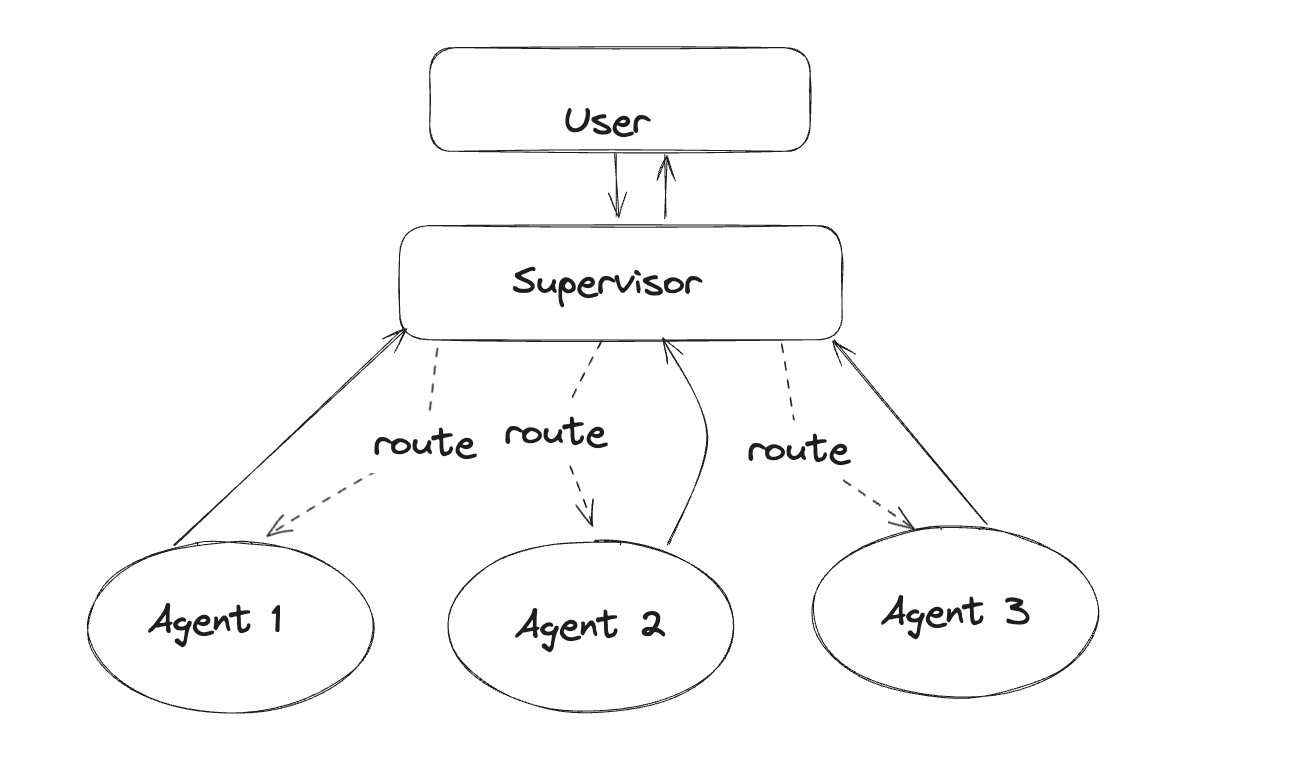
Below, we will create an agent group, with an agent supervisor to help delegate tasks and to simplify the code in each agent node, we will use the AgentExecutor class from LangChain.
Create Tools
For this example, you will create an agent to search the web with a search engine and an agent to retrieve the review from Activeloop datasets. Define the tools they’ll use below:
1from typing import Annotated, List, Tuple, Union
2from langchain_core.tools import tool
3from langchain.agents import AgentExecutor, create_openai_tools_agent
4from langchain_core.messages import BaseMessage, HumanMessage
5from langchain_openai import ChatOpenAI
6
7def create_agent(llm: ChatOpenAI, tools: list, system_prompt: str):
8 # Each worker node will be given a name and some tools.
9 prompt = ChatPromptTemplate.from_messages(
10 [
11 (
12 "system",
13 system_prompt,
14 ),
15 MessagesPlaceholder(variable_name="messages"),
16 MessagesPlaceholder(variable_name="agent_scratchpad"),
17 ]
18 )
19 agent = create_openai_tools_agent(llm, tools, prompt)
20 executor = AgentExecutor(agent=agent, tools=tools)
21 return executor
22
1def agent_node(state, agent, name):
2 result = agent.invoke(state)
3 return {"messages": [HumanMessage(content=result["output"], name=name)]}
4
Create the Agent Supervisor in LangGraph
It will use function calling to choose the next worker node OR finish processing.
1from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
2from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
3
4#members = ["Researcher", "QAAgent"]
5members = ["Researcher", "Reviewer"]
6system_prompt = (
7 "You are a supervisor tasked with managing a conversation between the"
8 " following workers: {members}. Given the following user request,"
9 " respond with the worker to act next. Each worker will perform a"
10 " task and respond with their results and status. When finished,"
11 " respond with FINISH."
12)
13# Our team supervisor is an LLM node. It just picks the next agent to process
14# and decides when the work is completed
15options = ["FINISH"] + members
16# Using openai function calling can make output parsing easier for us
17function_def = {
18 "name": "route",
19 "description": "Select the next role.",
20 "parameters": {
21 "title": "routeSchema",
22 "type": "object",
23 "properties": {
24 "next": {
25 "title": "Next",
26 "anyOf": [
27 {"enum": options},
28 ],
29 }
30 },
31 "required": ["next"],
32 },
33}
34prompt = ChatPromptTemplate.from_messages(
35 [
36 ("system", system_prompt),
37 MessagesPlaceholder(variable_name="messages"),
38 (
39 "system",
40 "Given the conversation above, who should act next?"
41 " Or should we FINISH? Select one of: {options}",
42 ),
43 ]
44).partial(options=str(options), members=", ".join(members))
45
46llm = ChatOpenAI(model="gpt-4-1106-preview")
47
48supervisor_chain = (
49 prompt
50 | llm.bind_functions(functions=[function_def], function_call="route")
51 | JsonOutputFunctionsParser()
52)
53
Define the Tools Functions
1@tool
2def FindBestReviewFromQuery(search:str):
3 """
4 Find the best review and return them
5 """
6 text_search_results = reviews_texts_lc.vectorstore.search(
7 embedding_data = [search],
8 embedding_function = clip.embed_documents,
9 k=200,
10 )
11 return text_search_results
12
13@tool
14def QAToolFunction(query):
15 """
16 Define the question answering model
17 """
18 retriever = reviews_texts_lc.as_retriever(
19 search_type = "similarity",
20 search_kwargs = {
21 "k": 20,
22 "embedding_function": clip.embed_documents,
23 "filter": {'metadata': {'title': 'Taqueria La Espuela'}}
24 }
25 )
26 qa = RetrievalQA.from_llm(llm, retriever=retriever)
27
28 return qa.run([query])
29
Construct Graph
We’re ready to start building the graph. Below, define the state and worker nodes using the function we just defined.
1import operator
2from typing import Annotated, Any, Dict, List, Optional, Sequence, TypedDict
3import functools
4
5from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
6from langgraph.graph import StateGraph, END
7from langchain_community.tools.tavily_search import TavilySearchResults
8
9# The agent state is the input to each node in the graph
10class AgentState(TypedDict):
11 # The annotation tells the graph that new messages will always
12 # be added to the current states
13 messages: Annotated[Sequence[BaseMessage], operator.add]
14 # The 'next' field indicates where to route to next
15 next: str
16
17tavily_tool = TavilySearchResults(max_results=5)
18research_agent = create_agent(llm, [tavily_tool], "You are a web researcher.")
19research_node = functools.partial(agent_node, agent=research_agent, name="Researcher")
20
21reviewer_agent = create_agent(llm, [FindBestReviewFromQuery], "You are a Review Retriever and take these from the Activeloop dataset")
22reviewer_node = functools.partial(agent_node, agent=reviewer_agent, name="Reviewer")
23
24#qa_agent = create_agent(llm,[QAToolFunction], "You can answer questions the user asks you")
25#qa_node = functools.partial(agent_node, agent=qa_agent, name="QAAgent")
26
27workflow = StateGraph(AgentState)
28workflow.add_node("Researcher", research_node)
29workflow.add_node("Reviewer", reviewer_node)
30workflow.add_node("supervisor", supervisor_chain)
31
Now connect all the edges in the graph.
1for member in members:
2 # We want our workers to ALWAYS "report back" to the supervisor when done
3 workflow.add_edge(member, "supervisor")
4# The supervisor populates the "next" field in the graph state
5# which routes to a node or finishes
6conditional_map = {k: k for k in members}
7conditional_map["FINISH"] = END
8workflow.add_conditional_edges("supervisor", lambda x: x["next"], conditional_map)
9# Finally, add entrypoint
10workflow.set_entry_point("supervisor")
11
12graph = workflow.compile()
13
Invoke the Team
With the graph created, we can now invoke it and see how it performs!
Invoke the Reviewer Agent
1for s in graph.stream(
2 {
3 "messages": [
4 HumanMessage(content="Retrieve restaurant reviews by the word 'burger'")
5 ]
6 }
7):
8 if "__end__" not in s:
9 print(s)
10 print("----")
11
Invoke the Researcher Agent
1
2for s in graph.stream(
3 {
4 "messages": [
5 HumanMessage(content="Find the best restaurant in Rome.")
6 ]
7 }
8):
9 if "__end__" not in s:
10 print(s)
11 print("----")
12
Summarizing the Findings
To conclude what is and is not possible in the context of restaurant insights, the OpenCLIP embeddings are surprisingly accurate in not just recognizing food in general, but also the particular dish. In combination with Deep Lake, it then provides valuable insights into the restaurant reviews and can help you better imagine what people enjoy eating in your neighbourhood. This can be especially helpful if the dining options are rich and it’s difficult to check restaurants one-by-one. The biggest weakness, however, is the data preparation process which is highly time-consuming. To scrape, process and ingest data from 130 restaurants, the total runtime was around 4.5 hours, nevertheless, there are still ways to make this faster and more efficient.
Overall, we see that the OpenCLIP embeddings are very powerful and can be very useful for LangChain as well, even though there is currently no integration. The highest potential we see in the unsupervised categorization and image search by text without any context, which as you could see worked pretty well and is far from being limited only to restaurant data.
Additionally, LangGraph played a significant role in enhancing our capabilities. It provided a framework for building stateful, multi-actor applications with LLMs, allowing us to coordinate multiple chains across multiple steps of computation in a cyclic manner. This facilitated efficient task distribution and coordination, particularly through the use of Agent Supervisor, which delegated tasks between independent agents within the system, orchestrating interactions and workflows effectively.
We hope that you find this article interesting and useful for your future projects and hopefully see you next time.
FAQs
What is CLIP Model in AI?
CLIP is a neural network developed by OpenAI that connects text and images efficiently by learning visual concepts from natural language supervision. It utilizes a simple pre-training task where the model predicts which text snippet is paired with an image from a set of 32,768 options. This approach allows CLIP to recognize a wide range of visual concepts in images, enabling it to be applied to various visual classification tasks without the need for extensive labeled datasets. Unlike traditional deep learning models that rely on costly manually labeled datasets, CLIP learns from text-image pairs available on the internet, reducing the dependency on expensive data collection processes.
What is LangGraph in LangChain?
LangGraph in LangChain is a library designed for building stateful, multi-actor applications with LLMs (Large Language Models). It is intended to be used with LangChain and extends the LangChain Expression Language to coordinate multiple chains or actors across multiple steps. LangGraph allows for adding cycles to LLM applications, particularly useful for agent-like behaviors where an LLM is called in a loop to determine the next action. LangGraph’s main purpose is to enhance LLM applications with cycles, unlike LangChain, which is optimized for Directed Acyclic Graph (DAG) workflows.
What is the difference between LangGraph and LangChain?
LangGraph and LangChain are related components within the LangChain framework. LangGraph is a library designed for building stateful, multi-actor applications with LLMs, focusing on coordinating multiple chains or actors across various steps. It extends the LangChain Expression Language to enable cycles in LLM applications, particularly useful for agent-like behaviors where actions are determined through iterative interactions.
On the other hand, LangChain is a broader framework for developing applications powered by language models. It offers composable tools, off-the-shelf chains, and integrations for working with language models. LangChain emphasizes context-awareness and reasoning capabilities, connecting language models to contextual sources and enabling them to reason based on provided context. In essence, LangGraph is more specialized in facilitating the creation of complex application structures involving multiple actors, while LangChain provides a comprehensive framework for developing diverse applications powered by language models.
Is LangGraph Free?
LangGraph is an open-source library, which means it is freely available for anyone to use. You can access and use LangGraph without any cost, subject to the terms of its open-source license. However, it’s essential to review the specific licensing terms associated with LangGraph to ensure compliance with its usage requirements.