



With the meteoric rise of large language models, companies are looking into integrating the technology across various business verticals - from creating marketing copy to customer service.
However, working with LLMs can be challenging, especially when building complex NLP applications. Enter LangChain, a powerful Python library designed to simplify the development process for LLMs. In this article, we’ll explore what LangChain is, how it works, and its primary benefits for large language models. In addition, we’ll showcase the official integration of LangChain and Deep Lake as an easy-to-use document store and how you can leverage Deep Lake to build question-answering assistants with LangChain.
For more Deep Lake + LangChain use cases, check out the following article:
- DataChad: Build a LangChain App to Chat with Any Data, from JSONs & CSVs to PDFs & Web URLs, Locally or in the Cloud
- Using LangChain, Deep Lake, & GPT-4 for Code Understanding: Exploring the Twitter Recommendation Algorithm
langchain uses deep lake by activeloop as a vector store
{kind=link}
What is LangChain?
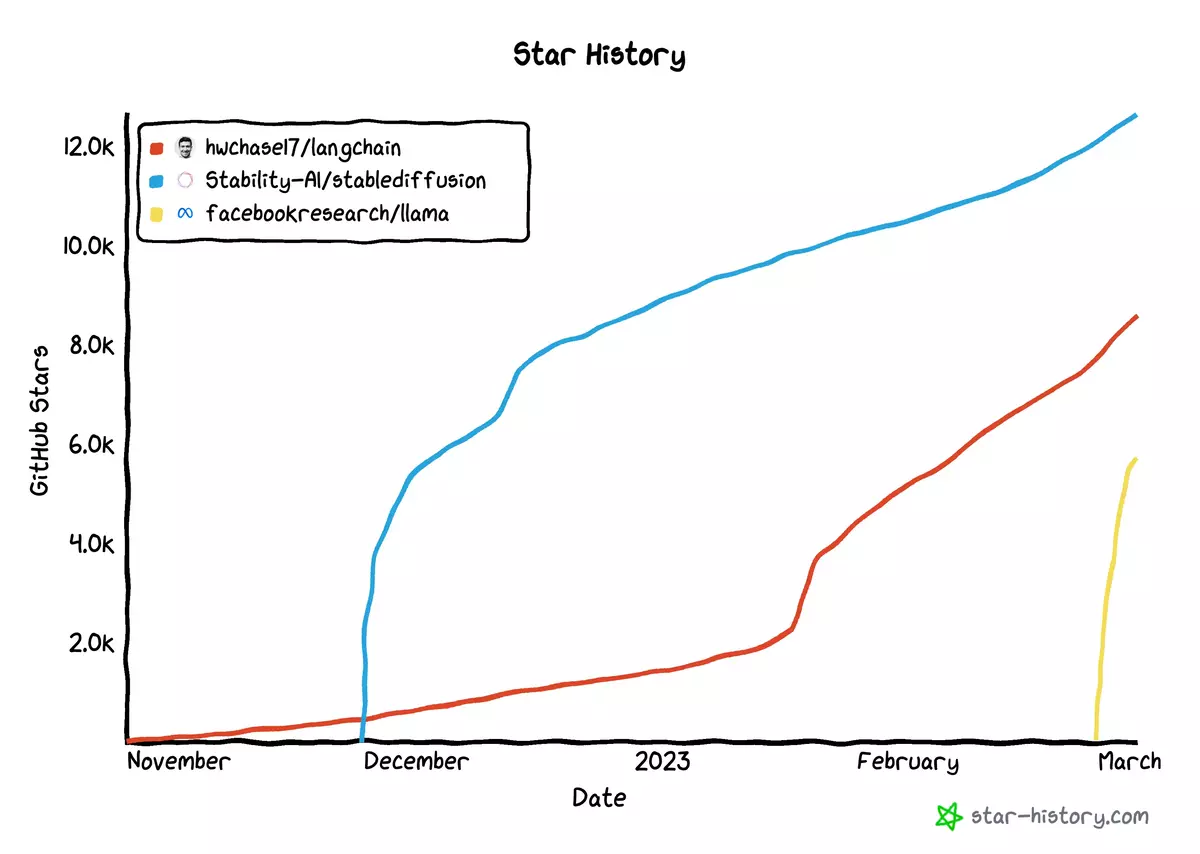
LangChain’s rise has been nothing short of impressive.
LangChain is a library that provides tools for working with LLMs. It streamlines the large language model development process by offering a chain of steps to generate text from a specific input prompt. The toolkit handles prompt input, text generation, and generated output manipulation. Effectively, it allows for developing conversational agents that use LLMs to generate natural language responses. These agents can be used for various applications, from supporting customers at scale to answering company-specifc questions based on your team’s internal Notion database.
How does LangChain work?
LangChain provides a pipeline of steps that generate text from input prompts. The pipeline comprises seven main components: input (prompt templates), the large language model, agents, utilities, document loaders, chains, indexes, and memory.
Input - LangChain Prompt Templates
The input component specifies the input prompt or the initial input provided to the pipeline (check out the most complete prompt engineering resource on GitHub). This comes in the form of a template that defines the structure of the prompt, including the format and content (sadly, no more Sydney for the foreseeable future 🙁). A typical example, for instance, could be asking the LLM to act as a machine learning expert or writing a bulleted list of possible answers.
Choosing the correct template is vital since a minor change in wording may significantly impact LLM performance - with up to 45% of improvement possible against the baseline with some methods.
Large Language Model
LangChain enables access to a range of pre-trained LLMs (e.g., GPT-3) trained on large datasets. The large language model component generates output (in this case, text) based on the prompt and input. These LLMs can further be fine-tuned to match the needs of specific conversational agents (e.g., if you are building a legal-specific chatbot). If you want to train your own LLM, check out how to train your Large Language Models (LLMs) efficiently.
Document Loaders
With Document Loaders module, you can ingest documents (e.g., pdfs of quarterly reports, powerpoints, etc., as we will do shortly!) into the LLM for further analysis (typically question answering).
LangChain Utils
LangChain provides an extensive collection of common utilities (Utils) to use in your application, such as Python REPLs (LLM would generate code to calculate the answer, run that code to get the answer and print it out), bash commands (e.g., to interface with the local system) or search engines, as well as a requests wrapper (to link a URL published post-2021 that ChatGPT doesn’t know about, for instance). Utils are employed to strengthen the potency of LLMs when interacting with other sources of knowledge or computation.
LangChain Agents
LangChain Agents make a call regarding which action should be taken next (e.g., a calculation should be handled by Wolfram Alpha, while a question about how old is the famous person might trigger a web search) to satisfy the directive given by the input. All the possible actions are chained together in a logical loop. In effect, you can use Tools (generic Utils, other chains, or even other agents) or a Toolkit (a group of tools) to minimize ChatGPT’s peculiarity of being very bad at answering math questions, and asking sophisticated questions, like “I’m 6 feet tall. How many feet longer is the circumference of the smallest moon of Jupiter compared to me?” (it’s less than you think).
Notably, Agents engage an LLM to decide which Action to take, execute that Action, see an Observation, and iterate until the goal is reached.
For the previous query, the Agent would act as follows:
Thought: Do I need to use a tool? Yes Action: PAL-MATH Action Input: The circumference of the smallest moon of Jupiter is 6 times longer than 6 feet. Observation: 36 Thought: Do I need to use a tool? No AI: The circumference of the smallest moon of Jupiter is 36 feet longer than 6 feet. The circumference of the smallest moon of Jupiter is 36 feet longer than 6 feet.
Chains
LangChain Chains, arguably, are THE component that makes LangChain stand out. LangChain provides a simple interface to go beyond a single LLM call, but rather enables users to link up LLMs or calls to LLMs and other Utils. The LangChain chains can be generic - a chain made up of links, which can be either primitives (prompts, LLMs, Utils, or other chains) or additional chains. In addition, chains can be sequential, meaning that multiple chains are run one after another, with prior outputs serving as inputs to the next-in-line chain link.
For instance, we used the Program-Aided Language Models in the previous example. Here, the chain takes user input (a reasoning question - “I’m 6 feet tall. How many feet long is the circumference of the smallest moon of Jupiter compared to me?”), and decides that no additional Utils must be used to answer the question.
Let’s try asking another question. “Alex has three times the number of balls as Ben. Ben has two more balls than Claire. If Claire has four balls, how many total balls do the three have together?”
pal_chain = PALChain.from_math_prompt(llm, verbose=True)
question = "Alex has three times the number of balls as Ben. Ben has two more balls than Claire. If Claire has four balls, how many total balls do the three have together?"
pal_chain.run(question)
> Entering new PALChain chain...
def solution():
"""Alex has three times the number of balls as Ben. Ben has two more balls than Claire. If Claire has four balls, how many total balls do the three have together?"""
claire_balls = 4
ben_balls = claire_balls + 2
alex_balls = ben_balls * 3
total_balls = alex_balls + ben_balls + claire_balls
result = total_balls
return result
> Finished chain.
'28'
Indexes
Language models are more powerful and valuable when combined with your own (proprietary) data. LangChain provides common indices for working with data - embeddings or, most commonly, a data store, such as Deep Lake.
LangChain Memory
Finally, LangChain includes a memory component. By default, Chains and Agents are stateless, which means they react to each new input query independently of prior inputs. Memory thus allows agents to recall previous interactions with users (a great use case for chatbots) or remember entities (e.g., recall all the Horcruxes Lord Voldemort created and who destroyed which one after you feed the entirety of Pottervers into it). This enables agents to provide users with more personalized and contextualized responses as time passes.
What are the top LangChain use cases?
Agents: LangChain provides a dedicated module for building agents, which are systems that use a language model to interact with other tools. They can be used to create chatbots or power the next generation of personal assistants.
Chatbots: Thanks to the Memory module, LangChain can be used to create chatbots, with the ability to remember what happened in previous interactions and the ability to recall distinct entities and answer questions based on them.
Data Augmented Generation: LangChain provides tools for generating text based on specific data, such as summarization of a specific text or question answering over one particular or multiple pieces of text.
Question Answering: As previously mentioned, LangChain can be utilized to perform question answering over your document data (powerpoints, pdfs, etc.), with the option to create an index over the data to save time and money (and, potentially, additional headcount on Research Assistants or Dedicated Knowledge teams - looking at you, consulting companies!).
Code Understanding: You can use LangChain to parse large code repositories, understand how certain variables are defined or how the functions interact. More interestingly, you can also create demo scenarios and ask LangChain how the code would perform in that scenario. We’ve written a guide on using LangChain to Chat with GitHub Code Repos (we’ve used the Twitter recommendation algorithm). Check it out!
Summarization: LangChain can synthesize an actionable summary of multiple longer documents, which helps distill long reports into the core pieces of information (or maybe even sifting through long and uninteresting email chains).
Evaluation: LLMs are notoriously hard to evaluate with traditional “hard” metrics. LangChain provides tools for assessing language models, specifically (data-augmented) question-answering systems.
Model Comparison: LangChain provides a ModelLaboratory for testing and comparing various alternatives of prompts, models, and even chains to use.
What are the main benefits of LangChain for large language models?
LangChain provides several benefits for developers working with LLMs. These comprise, but are not limited to:
Simplified development: LangChain streamlines the development process by providing a simple pipeline for generating text from input prompts. This saves time and effort for developers who would otherwise have to handle complex NLP tasks manually.
Improved accuracy: LangChain’s “chained” approach can enhance the accuracy of end result by ensuring consistency and coherence between the input prompts and the generated text. The model evaluation toolkit helps compare and improve the large language models you’re working on.
Customizability: LangChain’s flexible pipeline allows developers to customize it to their specific needs. This includes choosing different LLMs and combining them with utilities such as search engines, modifying the prompt template, or handling the generated output in a custom way. But, it also can work out of the box, offering a multitude of pre-built prompts and chains for standard use cases, such as question answering, summarization, and chatbots, so that users can rapidly build and deploy language model applications.
Interoperability: LangChain is built to integrate easily with various tools, data sources, and Python libraries, including Deep Lake, making it a stellar choice for building complex applications to solve multiple business problems.
Practical Example: Using LangChain and Deep Lake to Explore Amazon’s Revenue Growth Pre- and Post-Pandemic
In this tutorial, we will first load Amazon’s quarterly financial reports, embed using OpenAI’s API, store the data in Deep Lake, and then explore it by asking questions.
1!pip3 install langchain deeplake pypdf openai tiktoken langchain-openai
2
1from langchain_openai import OpenAIEmbeddings
2from langchain.vectorstores import DeepLake
3from langchain.text_splitter import CharacterTextSplitter
4from langchain_openai import OpenAI
5from langchain.chains import RetrievalQA
6from langchain_openai import ChatOpenAI
7from langchain.document_loaders import PyPDFLoader
8
Next, we need to get API tokens from OpenAI and Activeloop (learn how to receive an API token for Activeloop after registering).
1import os
2os.environ['OPENAI_API_KEY']='OPEN_AI_KEY_HERE'
3os.environ['ACTIVELOOP_TOKEN']='ACTIVELOOP_TOKEN'
4
Next, we need to get API tokens from OpenAI and Activeloop (learn how to receive an API token for Activeloop after registering).
First, let’s download financial reports from Amazon and load them into pages:
1import requests
2import tqdm
3from typing import List
4
5# financial reports of amamzon, but can be replaced by any URLs of pdfs
6urls = ['https://s2.q4cdn.com/299287126/files/doc_financials/Q1_2018_-_8-K_Press_Release_FILED.pdf',
7 'https://s2.q4cdn.com/299287126/files/doc_financials/Q2_2018_Earnings_Release.pdf',
8 'https://s2.q4cdn.com/299287126/files/doc_news/archive/Q318-Amazon-Earnings-Press-Release.pdf',
9 'https://s2.q4cdn.com/299287126/files/doc_news/archive/AMAZON.COM-ANNOUNCES-FOURTH-QUARTER-SALES-UP-20-TO-$72.4-BILLION.pdf',
10 'https://s2.q4cdn.com/299287126/files/doc_financials/Q119_Amazon_Earnings_Press_Release_FINAL.pdf',
11 'https://s2.q4cdn.com/299287126/files/doc_news/archive/Amazon-Q2-2019-Earnings-Release.pdf',
12 'https://s2.q4cdn.com/299287126/files/doc_news/archive/Q3-2019-Amazon-Financial-Results.pdf',
13 'https://s2.q4cdn.com/299287126/files/doc_news/archive/Amazon-Q4-2019-Earnings-Release.pdf',
14 'https://s2.q4cdn.com/299287126/files/doc_financials/2020/Q1/AMZN-Q1-2020-Earnings-Release.pdf',
15 'https://s2.q4cdn.com/299287126/files/doc_financials/2020/q2/Q2-2020-Amazon-Earnings-Release.pdf',
16 'https://s2.q4cdn.com/299287126/files/doc_financials/2020/q4/Amazon-Q4-2020-Earnings-Release.pdf',
17 'https://s2.q4cdn.com/299287126/files/doc_financials/2021/q1/Amazon-Q1-2021-Earnings-Release.pdf',
18 'https://s2.q4cdn.com/299287126/files/doc_financials/2021/q2/AMZN-Q2-2021-Earnings-Release.pdf',
19 'https://s2.q4cdn.com/299287126/files/doc_financials/2021/q3/Q3-2021-Earnings-Release.pdf',
20 'https://s2.q4cdn.com/299287126/files/doc_financials/2021/q4/business_and_financial_update.pdf',
21 'https://s2.q4cdn.com/299287126/files/doc_financials/2022/q1/Q1-2022-Amazon-Earnings-Release.pdf',
22 'https://s2.q4cdn.com/299287126/files/doc_financials/2022/q2/Q2-2022-Amazon-Earnings-Release.pdf',
23 'https://s2.q4cdn.com/299287126/files/doc_financials/2022/q3/Q3-2022-Amazon-Earnings-Release.pdf',
24 'https://s2.q4cdn.com/299287126/files/doc_financials/2022/q4/Q4-2022-Amazon-Earnings-Release.pdf'
25 ]
26
27def load_reports(urls: List[str]) -> List[str]:
28 """ Load pages from a list of urls"""
29 pages = []
30
31 for url in tqdm.tqdm(urls):
32 r = requests.get(url)
33 path = url.split('/')[-1]
34 with open(path, 'wb') as f:
35 f.write(r.content)
36 loader = PyPDFLoader(path)
37 local_pages = loader.load_and_split()
38 pages.extend(local_pages)
39 return pages
40
41pages = load_reports(urls)
42
We now use the Text Splitter Util to split documents into pages.
1text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
2texts = text_splitter.split_documents(pages)
3
4embeddings = OpenAIEmbeddings()
5
6db = DeepLake(dataset_path="hub://davitbun/amazon_earnings_6", embedding=embeddings, token=os.environ['ACTIVELOOP_TOKEN'])
7db.add_documents(texts)
8
9
Since the dataset is stored on Activeloop, you can load it later without recomputing embeddings. This is a significant benefit cause it would save you time and computational resources. LangChain has a wrapper around Deep Lake, allowing you to use it as a Vector Store.
1qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(model='gpt-3.5-turbo'), chain_type='stuff', retriever=db.as_retriever())
2
How to answer questions using ML?
The state-of-the-art method of question answering is by leveraging LangChain and Activeloop Deep Lake. You can store your documents in the unified, streamable format, and connect it to LangChain to run a question-answering model such as GPT or BERT. These language models are able to understand the context of the question and generate a more accurate answer. You may also implement techniques like data augmentation, document retrieval, and summarization to enhance the system performance.
Let’s now explore Amazon’s revenue change pre- and post-pandemic.
1qa.invoke("Combine total revenue in 2020?")
2#Amazon's total revenue in 2020 was $386,064 million.
3
This answer is obviously incorrect, as we didn’t use any sophisticated methods for addition. We will explore further optimization for this use case to consistently get good answers by employing a chain of agents. For now, however, more straightforward queries can be answered very quickly:
1qa.invoke("What is the revenue in 2021 Q3?")
2# The net sales for Q3 2021 was $110.8 billion, with a 15% increase to $127.1 billion in Q3 2022.
3
1qa.invoke("What is the revenue in 2023 Q1?")
2# The financial results for 2023 Q1 are not provided in the given context
3
Obviously, the question answering works only on the given data, that is limited to 2022. To answer more current questions, we should connect LangChain to agents like GoogleSearchAPIWrapper. We will explore this in a further article.
No more switching tabs between reports! Just feed the entirety of the information to LangChain and store the converted text in the Deep Lake format for immediate answers.
You can also use the Colab Notebook to streamline the development.
Concluding Remarks: Use LangChain & Activeloop for efficient LLM training
In conclusion, LangChain is a robust tool for productizing large language models, providing a simple workflow to generate output by employing prompts, utilities, and language models in a linked fashion. It offers numerous benefits, including streamlined LLM development, improved accuracy of LLMs, better use-case customization, easy integration with data sources, and other Python libraries, including Activeloop Deep Lake. Deep Lake, in its turn, enables rapid LangChain prototyping, as you can immediately access data without the need to recompute the embeddings for the model finetuning. If you’re working with LLMs and looking to streamline your development process, LangChain, powered by Deep Lake as the data store for LLM training, is worth exploring.
LangChain FAQs
What are the main LangChain modules?
The main modules of LangChain include prompts, LLMs, document loaders, vector stores like Deep Lake, utils, chains, indexes, agents, memory, and chat.
Can I use LangChain to query financial data?
Yes. With Deep Lake as your vector store, you can store your financial pdfs or csv files and their embeddings and ask questions on top of your financial data.
How can I get started with LangChain?
Research: After reading this ultimate guide, familiarize yourself with the LangChain project, its goals, and its underlying technology. Read the documentation, and explore related LangChain articles to build a solid foundation.
Join the Community: Connect with the LangChain community discord and follow them on Twitter to stay updated on the latest developments.
Experiment with LangChain Sample Projects: Start by experimenting with sample projects for code understanding, building chatbots or answering questions over specific documents or webpages.
How does LangChain help with prompt management and optimization?
LangChain provides prompt templates and various agents that can use LLMs to decide what actions should be taken. In theory, you can use LangChain to iteratively optimize your prompts.
How old is LangChain?
LangChain is was launched in October 2022. At the time of writing this article, it was approximately 7 months old.
Is LangChain open-source?
Yes, LangChain is is fully open-source and comprises Python and Javascript libraries.
What is the use of LangChain?
LangChain allows users to build advanced AI applications using large language models (LLMs) for various tasks, such as chatbots, Generative Question Answering (GQA), code understanding or summarization. The library is designed to “chain” together different components, including prompt templates, LLMs, agents, and memory, to create sophisticated use cases around LLMs. LangChain supports both OpenAI’s GPT family of models, as well as open-source alternatives, offering flexibility and adaptability for developers.