



Introduction: the History of Queries: from Papyrus Scrolls to Text to SQL, enabled by GPT-4
Querying datasets has been a crucial aspect of database management systems since their inception. It is the process of extracting data from a database based on specific criteria. Over the years, querying has undergone significant changes, from simple command-line interfaces to complex graphical user interfaces and, most recently, natural language processing. In this blog post, we will review each notable milestone in the evolution of sending commands to manipulate database data. While we’ve previously focused on the evolution of data storage, covering the development from Oracle to Databases for AI, this blog post will mainly focus on the querying side of things. We will also introduce the next step in the querying lifecycle - talking to the databases in natural language, as you would talk to your business intelligence analyst or data engineer.
But first, let’s get to the basics.
Retrieving Data pre-1960s
In 1945, magnetic tapes were developed as the first medium for searching data, replacing punch cards and paper tape. In the 1950s, with the increasing use of computers and the installation of the first commercial computer in 1957, the need for a more efficient and standardized way of accessing data became apparent. 1959 saw McGee propose generalized
access to electronically stored data, and IBM introduced the Ramac system. As a result, analysts could read data in a non-sequential manner, and access to files became feasible.
The 1960s: The onset of computerization requires querying
In the 1960s, the advent of cost-effective computers enabled private organizations to begin storing data electronically, marking the start of computerized databases. Two dominant data models characterized this era: the network model known as CODASYL and the IMS hierarchical model. Among these models, the SABRE system emerged as a commercial success, allowing IBM to help American Airlines effectively manage its reservation data. The set was being staged for the first (truly) relational database systems to be designed in the next decade
The 1970s: Relational databases are born, and SEQUEL evolves
The 1970s saw the emergence of the relational model, proposed by Edgar F. Codd. The relational model allowed data to be stored in tables, making it easier to retrieve and manipulate data. Inspired by this, Donald D. Chamberlin and Raymond F. Boyce, at IBM’s San Jose location (quite close to Activeloop’s HQ), developed the Structured English Query Language (SEQUEL). After several attempts at creating a relational database language involving multiple experiments, puns on the query language of Ingres (QUEL), and a trademark issue with a British aircraft manufacturing company forcing them to drop the vowels, they settled on SQL. Next, IBM began developing commercial products based on their System R prototype. In 1979, Relational Software introduced Oracle V2, one of the first commercially available implementations of SQL.
The 1980s: Road to SQL becoming a global standard
With the rise of the development of personal computers, database management systems (DBMS) such as DBASE and PARADOX were created to allow PC users to manipulate and define data. However, these systems lacked insulation between programs and data and didn’t support multiview or multiaccess capabilities. As computer sales rapidly increased, relational database systems emerged as a commercial success, leading to a decline in the popularity of network and hierarchical database models. IBM’s DB2 became a flagship product, and the introduction of IBM PC led to the establishment of new database companies and the creation of various products, including PARADOX, RBASE 5000, RIM, Dbase III and IV, OS/2 Database Manager, and Watcom SQL. Finally, ANSI (1986) and ISO (1987) officially adopted the standard “Database Language SQL” language definition, cementing SQL as the dominating query language for the years to come.
The 1990s: Object-oriented databases emerge
In the 1990s, the database industry saw the emergence of object-oriented databases (OODBs) that allowed for the storage of complex data structures and retrieval using object-oriented query languages like OQL and QBE. This decade saw the demand for extending DBMS capabilities to meet new applications, the emergence of commercial object-oriented DBMSs, and the demand for developing applications utilizing data from various sources and of different modalities (temporal, multimodal, etc). Furthermore, the decade saw the emergence of standards for data query and exchange (SQL2, PDES, STEP) and the extension of DBMS capabilities to heterogeneous and multi-database systems. The advent of the internet in the middle of the decade led to exponential growth in the database industry, with average desktop users accessing client-server database systems to access computer systems with legacy data. The introduction of GUI-based database management systems, such as Microsoft Access and Oracle Forms, made querying more accessible to non-technical users. These systems allowed users to create queries by selecting options from drop-down menus and forms. What is more, the decade saw increased investment in online businesses resulting in a rise in demand for internet database connectors such as Front Page, Active Server Pages, Java Servlets, and more.
Finally, in 1998, Carlo Strozzi coined the term “NoSQL” when naming his database Strozzi NoSQL. Although it was still de facto relational, it would significantly impact querying in the new millennium.
The 2000s: Querying goes mainstream
During the 2000s, natural language processing (NLP) was increasingly used in querying, allowing non-technical users to retrieve data by asking questions in plain language. NLP-based systems such as Wolfram Alpha and Google’s Knowledge Graph enabled users to retrieve relevant information from databases. Despite a dot-com bubble burst-driven decline in the early 2000s, database applications continued to grow, with new interactive applications developed for PDAs, point-of-sale transactions, and consolidation of vendors. The leading database companies in the western world were Microsoft, IBM, and Oracle. It wasn’t until 2009 that NoSQL became more widespread by organizing an event to discuss non-relational databases (thanks, Johan Oskarsson!). Today, NoSQL databases enjoy wide adoption, which we will cover in the next section.
The 2010s: the rise of NoSQL, MongoDB, Snowflake, & Databricks
The 2010s saw the rise of big data and the need for more advanced querying techniques. NoSQL databases, such as MongoDB and Cassandra, emerged as viable alternatives to traditional relational databases. These databases allowed users to store and query large volumes of unstructured data. In addition, machine learning and artificial intelligence (AI) techniques were integrated into querying systems, allowing users to ask more complex questions and retrieve more relevant information. I’ve covered the differences between the options, including Lakehouse (and Photon) and Data Lake, in this article, in case you’re interested.
The Future of Querying Datasets
Querying data has come a long way since its inception in the 1960s (or scrolling through papyrus rolls by Egyptians starting around 3000 BCE). The evolution of querying has been driven by advancements in computer technology, the rise of non-technical users, and the need for more advanced querying techniques. Today, querying is an integral part of database management systems, and with the advancements in AI and machine learning, it is set to become even more accessible and efficient.
We are not fans of crystal balls, so instead of hypothesizing what the future of querying would look like, we attempted to build it. Enter querying for machine learning, with natural language as an input.
Hello, Text To SQL (or, in our case, Text to TQL)
What is Text to SQL? It is a technology that converts natural language queries into SQL code. It is rapidly gaining popularity due to its ability to simplify querying databases, particularly for non-technical users. Text to SQL was enabled with hard work from various researchers, including companies like Salesforce, that released the crowdsourced the WikiSQL dataset, containing queries in SQL and natural language prompts. If interested, check out their work, including the Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning.
With Text to SQL, users can ask questions in plain English and get the desired results without having to write complex SQL queries. Naturally, this saves time and increases efficiency. Simplifying the process of querying databases, Text to SQL eliminates the need for extensive training or knowledge of complex SQL commands. In addition, Text to SQL can help bridge the gap between technical and non-technical teams, making it a valuable tool for businesses.
Another benefit of Text to SQL is its ability to increase data accessibility. By allowing users to query databases using natural language, it reduces the need for manual data processing and interpretation, which can result in faster access to information. This can be particularly beneficial in industries where quick access to data is critical, such as finance, healthcare, and e-commerce.
Having this in mind, we decided to ship Text to TQL to simplify querying complex datasets like Imagenet or COCO dataset and ease both technical and non-technical users into machine learning datasets exploration.
Introducing Automated Tensor Query Language, powered by Large Language Models
What is TQL? Tensor Query Language (TQL) powerful dataset query engine built by Activeloop in C++, optimized for Deep Lake datasets, enables users to filter relevant data in data science workflows. Queries can be performed both in the UI and in the Python API. The resulting Dataset Views can be saved, loaded, and passed to machine learning frameworks for analysis. Dataset query syntax includes various operators like CONTAINS, ==, SHAPE, LIMIT, AND, OR, NOT, UNION, INTERSECT, ORDER BY, ANY, ALL, and SAMPLE BY, enabling flexible querying of datasets.
In our most recent update, TQL leverages the power of machine learning models and algorithms to understand and interpret natural language queries and then provides relevant results based on the user’s input. Thus with TQL, users can query datasets based on the labels, or tags, associated with the data. This makes it easier to find and retrieve specific data points that match certain criteria without needing to know the underlying structure or format of the dataset. Text to TQL is a powerful new tool for data scientists, machine learning engineers, and anyone working with large datasets who wants to quickly and efficiently find and analyze specific data points.
SQL Query Where Contains, but slightly different
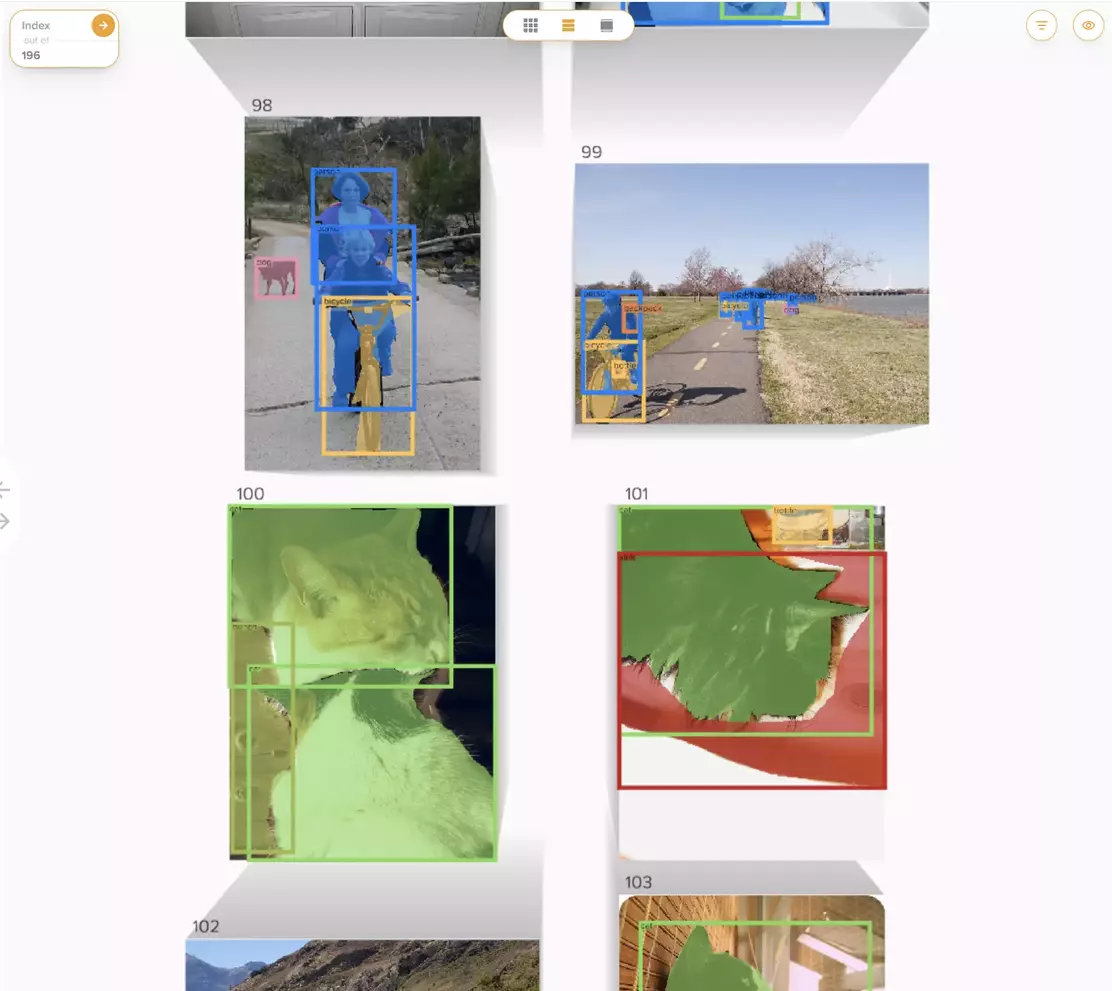
So how does this work? Imagine you’re working on the COCO training dataset, and need to build a simple classifier to discern between cats and dogs.
Show me 100 images of dogs and 100 images of cats
You type this text into the upper box and hit run. Almost instantly, we return the actual query:
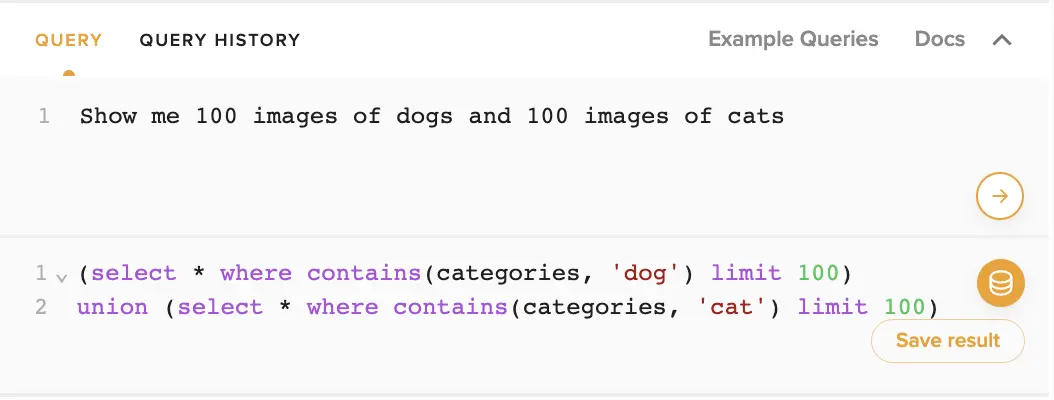
And we also run it for you, so you automatically have your data.
Apart from labels for image data, you can also query other modalities, e.g., text data. Let’s consider Stanford Question Answering Dataset (SQuaD dataset). The dataset consists of a set of questions and answers to them.
show me data where the question contains France and the context contains Paris
The UI will generate the query:
1select * where contains(question, 'France') and contains(context, 'Paris')
2


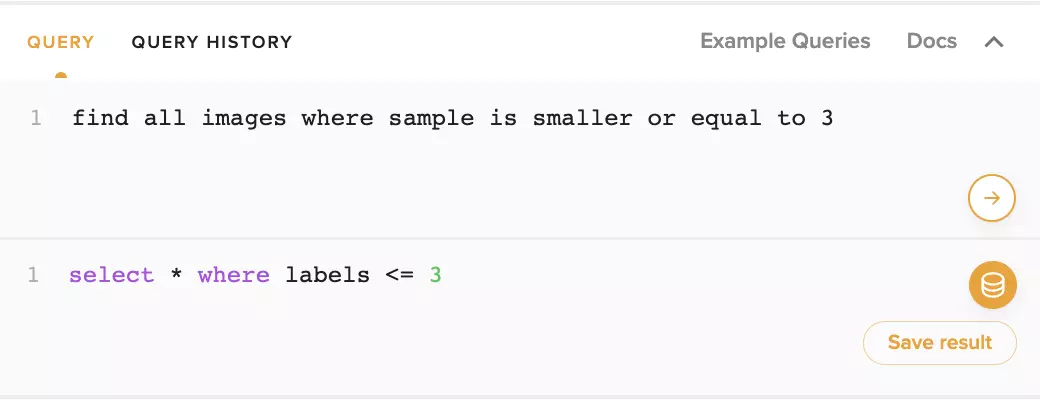
Text to TQL can also handle basic computational queries. Let’s try a simple query on MNIST.
find all images where the sample is smaller or equal to 3
Or,
So, what is Behind Text to SQL?
GPT-4
Since it’s release a mere week ago, GPT-4 (Chat-GPT’s younger but stronger cousin) has been making waves across the Twitterverse and the industry. Companies (including us!) are already integrating it in their day-to-day operations to improve the user experience. We, too, wanted to make our users productive. :)
What is GPT-4?
GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs - for now only for limited cases, though). It is a transformer-based model pre-trained to predict the next token in a document. Its post-training alignment process improves performance on measures of factuality and adherence to the desired behavior (API users can specify to a certain extent as “system requirements”).
How does GPT-4 compare to ChatGPT/GPT-3.5?
Compared to ChatGPT and GPT-3.5, GPT-4 demonstrates human-level performance across various professional and academic benchmarks, including passing a simulated LSAT test with a score around the top 10% of test takers (ChatGPT, in contrast, resides in the bottom 10% for the same test). It also outperforms previous large language models and most state-of-the-art systems on traditional NLP benchmarks and exhibits strong performance in non-English languages."
What are GPT-4 Advantages?
One advantage of GPT-4 is its capability to process both image and text inputs, expanding its potential use cases in dialogue systems, text summarization, as well as machine translation. Additionally, it exhibits improved performance on measures of factuality and adherence to the desired behavior.
GPT-4 Disadvantages
Nonetheless, like earlier GPT models, GPT-4 is not fully reliable and can suffer from “hallucinations,” has a limited context window, and does not learn from experience.
To tune GPT-4 for our use case, we have fed it countless examples of correct TQL queries for various datasets (of different modalities and schemas). For our use case, we noticed that GPT-4 currently walks a fine line between being to “verbose” and generous. For instance, for a query “find all things related to trees” it may produce a result that contains lemons (as they grow on trees) or even cliffs (…? Our guess is as good as yours here). On the other hand, it sometimes can err in over-relying on user-specified query. For example, Imagenet does have entire schools of fish (enough to build an entire education system, might I add). Asking TQL + GPT-4 to find all the fish in dataset might result in the following:
1 select * where contains(labels, 'fish')
2
When the actual expected query could have been:
1 select * where any(contains(labels, 'shark'), contains(labels, 'ray'), contains(labels, 'pike'), contains(labels, 'trout'), contains(labels, 'bass'), contains(labels, 'salmon'), contains(labels, 'eel'), contains(labels, 'sturgeon'), contains(labels, 'coho'), contains(labels, 'barracouta'))
2
and so on…
One thus should be cautious when using the outputs of GPT-4, particularly in contexts where reliability is important. However, we are working at making this as reliable as possible. Whatever the case, we are confident this is the right step forward: out of hundreds of tests we’ve conducted, the new feature outperformed first-time query users whopping 99% of the time.
Concluding Remarks
In sum, querying databases has come a long way since the dawn of magnetic tapes in the 1940s. From punch cards to natural language processing, the evolution of querying has been driven by advancements in computer technology and the need for more accessible and efficient methods for extracting data from databases. The recent emergence of Text to SQL technology, including our own Text to TQL, has revolutionized the querying process by allowing users to retrieve data from databases using plain English queries. This technology saves time, increases efficiency, and makes querying more accessible even to non-technical users. Try out Text to TQL yourself and experience the benefits of simplified, efficient querying for complex datasets such as Imagenet dataset to explore the data, as well as to train and edit it with data lineage or evaluate ML model performance.
Query FAQs
What is a Database Query?
A database query is a request for information from a database. It usually involves some form of filtering or selecting data based on specific criteria or conditions. Queries are used to retrieve data, perform calculations or transformations on that data, and to combine data from multiple tables or sources. They are an essential part of database management and support a wide range of applications and business processes. Queries can be written in different programming languages or using graphical user interfaces provided by database management systems. The most common query language used today is Structured Query Language (SQL), used for relational databases.
How long does it take to learn SQL?
According to Berkley, the basics of SQL can be learned in 2 to 3 weeks due to its relative simplicity, but higher fluency requires additional time. Learning independently can take up to six months or longer. With Text to SQL, non-technical users need not learn how to code to easily access their data, which can result in faster and more accurate decision-making.
When to use NoSQL vs. SQL?
When choosing between SQL and NoSQL databases, it’s crucial to evaluate your application’s unique needs. SQL databases are an ideal choice for applications that demand complicated queries and data consistency. They’re also useful for applications that must abide by strict data integrity rules since they can manage complicated transactions and contain well-defined schemas. SQL databases perform best for applications that handle heavy write loads and data relationships, such as e-commerce websites and financial systems. Naturally, the expected datatype is structured (tabular).
When to use NoSQL? In contrast to SQL databases, NoSQL databases are a better fit for applications that require high scalability and flexibility, especially when managing unstructured or semi-structured data. They can effectively manage large volumes of data, including non-tabular and non-relational datasets, and are tailored to high-performance, distributed environments. Big data and real-time analytics applications, content management systems, and mobile applications prioritizing speed & scalability are great use cases for when to use a NoSQL database.
Ultimately, selecting between SQL and NoSQL hinges on your specific demands, including the size and intricacy of your data, the type of queries you need to execute, and the scalability and flexibility you demand. Here’s a brief table summarizing the differences between SQL vs NoSQL databases. We’ve also added TQL comparison, with TQL being powered by Deep Lake.
| Criteria | SQL | NoSQL | TQL |
|---|---|---|---|
| Data Structure | Structured data | Unstructured data | Both unstructured and structured data, higher performance on unstructured |
| Data Volume | Relatively smaller data sets | Very large and rapidly growing data sets | Dataset size irrelevant, handles rapid scalability for more than 1B rows |
| Data Relationship | Complex relationships and joins between tables | Simple or no relationships between data | Relationship-agnostic |
| Scalability | Vertical scaling (adding more resources to a single server) | Horizontal scaling (distributing data across multiple servers) | Both horizontal and vertical scaling |
| ACID Compliance | ACID compliant (Atomicity, Consistency, Isolation, Durability) | Mostly eventual consistency | ACID compliant |
| Transactions | Supports complex transactions with rollbacks and commits | Does not support complex transactions | Supports complex transactions with rollbacks, commits and time travel |
| Performance | Optimized for complex queries on a few large data sets | Optimized for many simple queries on large and rapidly changing data sets | Optimized for complex queries on any amount of large and rapidly evolving datasets |
| Flexibility | Rigid schema structure | Dynamic schema structure | Dynamic schema structure |
| Cost | High cost for large data sets | Lower cost for large data sets | Ultra low cost for large data sets and related machine learning training processes on them |
| Use Cases | Suitable for financial, e-commerce, and other transactional applications | Suitable for real-time data analytics, social media, and IoT applications | Suitable for generative AI, machine learning and computer vision use cases on multi-modal data |