



The world of AI is like a bullet train, and we’re all on it.
Generative AI emerged as the new gold rush in 2023, promising opportunities for innovation and unlocking economic upside- more precisely, growing the AI market from $44 billion in 2023 to $110.7 billion in 2026 (Statista, 2024), with Generative AI adding as much as $4.4 trillion in economic value globally (McKinsey & Co., 2023). However, for this potential to be fully realized, a robust data infrastructure is indispensable, serving as the railroads did during the gold rush era: essential pathways that enable rapid material access, movement, and growth.
When we started building Activeloop in 2018, our focus was on solving a critical challenge that many had yet to recognize: managing large, complex, unstructured datasets for AI. Inspired by my experience in neuroscience research on petabyte-scale data at Princeton, we embarked on a journey to simplify how large-scale datasets could be leveraged for AI. Our mission was clear from the start: empowering anyone to organize complex unstructured data and retrieve knowledge with AI.
Funnily, one of Activeloop’s earliest customers wanted a model to search through 80 million legal documents. Not only did they manage to slash training time from two months to just one week with us, but we also inadvertently built a large language model while transformers were one year old—even before OpenAI released the GPT family of models.
Today, as we announce our $11 million in Series A funding from Streamlined Ventures, Y Combinator, Samsung Next, Alumni Ventures, and Dispersion Capital, we are writing this blogpost to reflect on the past, present, and future of AI data and explain why we have built Deep Lake, the database for AI.
The Present State of AI Data Landscape
To start, let’s level-set on what we have in the present:
Multi-modal gives leverage, but unstructured, complex data is siloed.
Multi-modal AI can understand, interpret, reason, and generate across various forms of data—text, image, video, or even MRI scans—offers immense leverage. We’ve seen this first-hand with our enterprise clients across industries, now leveraging AI enterprise search to work across data types they’d collected but couldn’t fully use. Multi-modality offers more profound insights, nuanced interactions, and previously unimaginable solutions. However, the reality is that much of this complex, unstructured data remains siloed, untapped by the long tail of databases designed for simpler, structured data. This untapped potential represents both a challenge and an opportunity for innovation in data management and utilization. In fact, Gartner predicts that multi-modal AI will transform the operations of up to 75% of Fortune 500 companies.
Both fine-tuning models and accurate knowledge retrieval into the context of the models are essential. Both retrieval augmentation (RAG) and fine-tuning are essential in the context of GenAI as they address different limitations and challenges associated with LLMs. Fine-tuning allows for adapting the model to specific domains and tasks by adjusting its weights based on labeled data, mitigating issues like underperformance, biases, and limitations. On the other hand, RAG inserts relevant information as context before generating responses, providing up-to-date information and improving factual accuracy. While fine-tuning is effective for slow-to-change use cases, RAG excels in quick-to-change scenarios like incremental updates. Long-context LLMs do not seem to be the solution to the accuracy problem (Liu et al., 2023) and new research suggests that combining the two approaches is the most effective approach (Zhang et al., 2024), so seems like both methods are here to stay.
The moat is fast training iterations using collected data, but building a data flywheel is hard.
What we hear from our customers as all new research budgets are getting allocated to GenAI initiatives is: "How can we improve faster in unlocking value with AI?". The ability to iterate quickly in training models, leveraging the collected data in real life, is emerging as a critical competitive advantage—a moat protecting the leading entities in this space. We have seen this with Tesla’s data flywheel or with Dall-E and Midjourney being able to dominate the image generation niche. However, not every company can throw hundreds of millions of dollars into building in-house solutions to address this and keep investing to maintain them. Tesla, for instance, built an infrastructure to scale up to 200 petabytes of multi-modal data, running training on up to 14,000 GPUs.
A crucial challenge becomes apparent as we embrace the era of generative AI, with its promise of multi-modal capabilities and the necessity for swift, effective model iterations. The existing data management frameworks are ill-equipped for the rapid evolution required by next-generation AI technologies like RAG or fine-tuning, including developing a fast data flywheel. So, what does the ghost of “AI data management’s past” look like?
Why the 2010s Data Stack is Not ‘Modern’ Enough for Gen AI
1. The long tail of complex data untouched by databases is costly to use for AI.
As the GenAI landscape rapidly expands, it encounters a significant bottleneck: the vast, untapped reserves of multi-modal data—ranging from images and videos to MRI scans—remain largely inaccessible due to the limitations of traditional data management systems and formats. Anywhere between 73% to 97% of company data sits unused. But if one were even to try and use the data for AI, it would be either very hard or challenging and cost-prohibitive. Traditional databases (and even leading vector databases) store data in the working memory to run queries fast, but in-memory storage is extremely expensive as AI data gets big. Resorting to virtually attached disk storage solutions, such as EBS, EFS, and FSX, incurs significant expenses. While object storage options like S3, GCS, or MinIO present more budget-friendly storage solutions, their drawback lies in their higher latency performance when it comes to fast querying or model training.
2. Fragmented AI Data Stack with the missing gap between production and training AI data
The AI data stack is fragmented now more than ever. It creates a palpable gap between the production environments where AI models operate and the training grounds where they learn. This gap obstructs the seamless data flow, complicates the ML development cycle, and prevents organizations from creating the 'data flywheel’. Addressing this gap requires rethinking the AI data stack, integrating solutions that streamline the transition from training to production, and ensuring that AI models can continuously learn from new data and improve over time. This integration is pivotal for creating AI systems that are both dynamic and robust, capable of meeting the ever-changing demands of the real world.
3. Data scientists waste cycles translating data across tools to achieve their goals.
The ecosystem of tools and platforms surrounding AI data management is unnecessarily complicated. Feature stores, data orchestration tools, preprocessing utilities, cloud, and on-prem storage solutions, catalogs, fabric, and mesh - are a hot mess. This complexity hinders the seamless transition between AI model training and production environments. Moreover, engineers and data scientists pay the ‘integration tax’ to frankenstein these disjointed systems together to prepare data ready for AI. Often, the solutions they come up with are not standardized across the organizations, which further complicates the fast iteration cycles for the company as a whole. Such inefficiencies underscore the pressing need for a unified, streamlined approach to data management that can appropriately support the lifecycle of GenAI applications.
In sum, the 2010s data stack is not ‘modern’ anymore. We need a more streamlined system to support constantly updating, complex data, unified in a way native to AI.
Something like this:
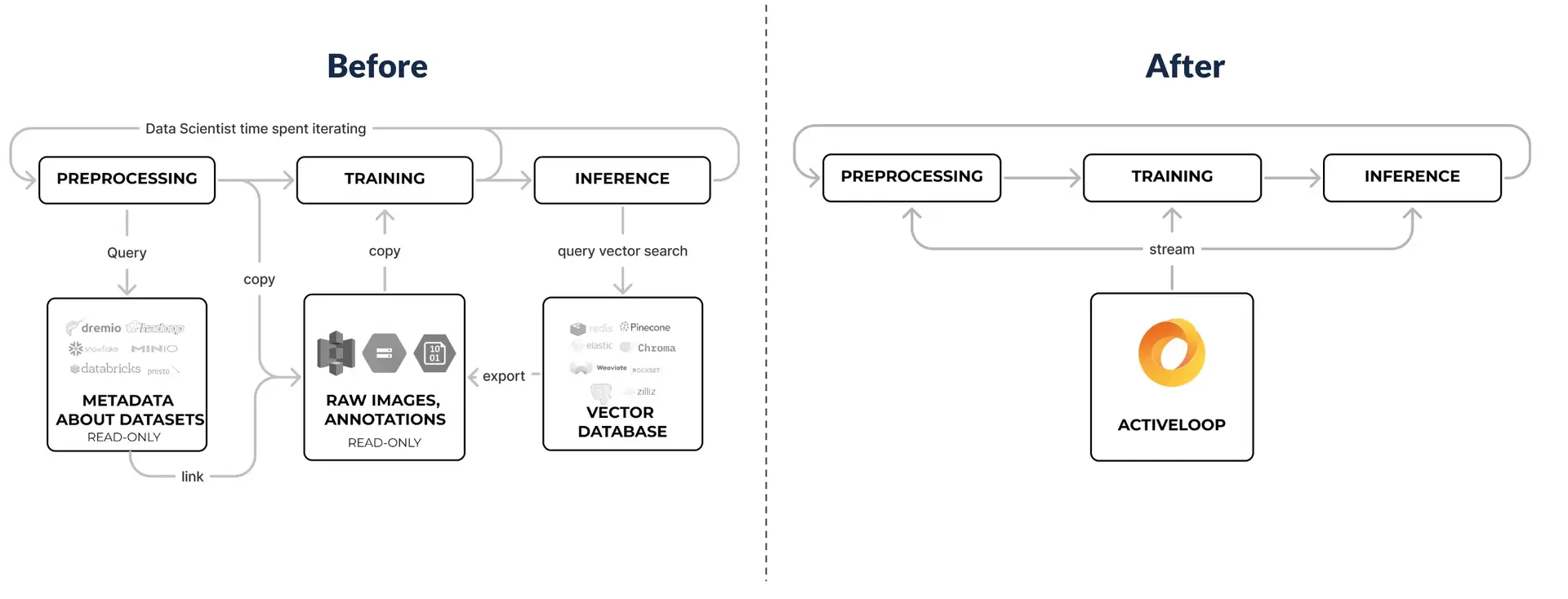
Enter Deep Lake, the Database for AI
Deep Lake is:
1. Serverless: Compute & Storage Isolation
Serverless architectures, where computing and storage components operate independently, offer significant benefits for AI applications. This model allows for scalability and flexibility, ensuring that resources are available on-demand without the overhead of managing physical servers (and the prohibitively high costs of in-memory databases). For AI, where computational needs can spike unpredictably based on the data processing workload, such an architecture ensures that resources are efficiently allocated, minimizing costs while maximizing performance - that is how we are up to 75% cheaper than anyone else on the market. Deep Lake addresses the compute and storage isolation and facilitates the efficient (and best-in-class; Ofeidis et al., 2022) handover of data to compute, fully utilizing the GPUs for model training
2. Multi-modal: Store Embeddings, Text, Audio, Images, and Videos
Deep Learning or Foundation Models algorithms expect tensors (or multi-dimensional arrays) as inputs. Activeloop allows for neatly storing this complex, unstructured data in a tensor format so companies can fully harness all the information they have for AI, achieving more precise results and enabling more use cases. When planning your AI strategy for the next five years, prioritize developing a robust and scalable architecture over creating a solution that merely impresses in demos on Twitter. To put it in another way, do not show up with just vectors to a tensor gunfight. You will lose the necessary depth to build more robust, bigger value-add systems that use all of your data.
3. All-in-one: Stream, Query, & Visualize
Deep Lake lets you stream, query, and visualize data within a single platform, dramatically simplifying the AI development process. It allows data scientists to seamlessly transition between different stages of AI model development—from data preprocessing and exploration to training and evaluation. Activeloop’s built-in features of a SQL-like Tensor Query Language (TQL) and its data visualization capabilities represent a significant step forward in this direction. By providing a unified platform that supports these functionalities, enterprises can accelerate their AI initiatives, reducing the time from data to insights.
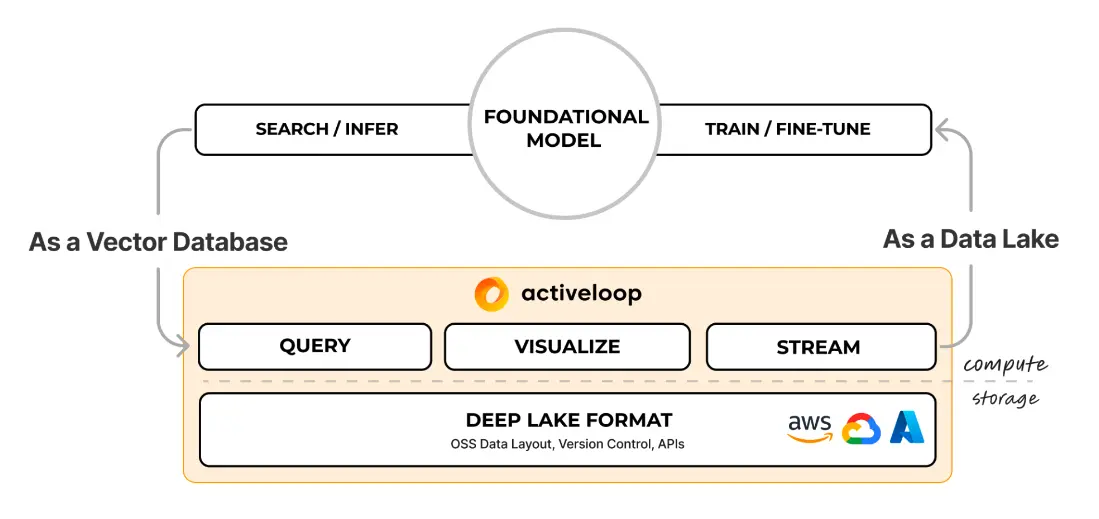
4. Enterprise-Ready
We serve several sensitive industries, like life sciences, MedTech, and legal, that prioritize security and regulatory compliance. Activeloop’s compliance with SOC 2 Type II standards, alongside Deep Lake’s SAML/Role-Based Access Control features, and ability to operate across clouds and local storage options ensure that stringent security and privacy requirements are met seamlessly with minimum impact on existing architectures. Deep Lake’s embedded architecture simplifies on-premise setup with minimal coding effort and guarantees that enterprises can securely manage their private data without an intermediary, keeping it away from third-party access.
Furthermore, the innovative Deep Memory feature, an enhancement built atop Deep Lake, significantly improves knowledge retrieval accuracy—by an impressive 22.5% on average—without impact on cost or latency. This capability is particularly beneficial in sensitive sectors, such as legal, where a leading law firm, Ropers Majeski, achieved an 18.5% increase in lawyer productivity with our customer Hercules.ai’s Generative AI solution and Intel® Xeon® processors.
Case Study: How Bayer Radiology Uses Database for AI to Disrupt Healthcare with GenAI
One of our Fortune 500 clients is Bayer Radiology, a unit of pharmaceutical and biotech company Bayer. The team faced challenges with the time-consuming data preparation process for AI. Developers had to manage multi-modal data subsets, control data versions, and continually integrate new data into their projects.
Bayer Radiology’s team dealt with multimodal data. Activeloop’s Deep Lake unified these different data modalities into a single storage solution, streamlining data pre-processing time. From start to finish, Deep Lake was deployed in under two weeks at Bayer Radiology. It enabled ‘chat with X-rays capability,’ so data scientists can efficiently query their data in natural language and use it for downstream machine learning training.
“It’s next-level. We’ve enabled a new human-machine interface that is natural to use and yields high-accuracy results for end-users”
– Steffen Vogler, Principal Imaging Technology Scientist, at Bayer Radiology, a unit of Bayer
Where is Deep Lake Headed Next?
We are thrilled to have partnered with investors like Streamlined Ventures, Y Combinator, Samsung Next, Alumni Ventures, and Dispersion Capital, among others, to continue onboarding enterprises to the Database for AI. This also means making Deep Lake faster, simpler, and more valuable.
Here is a sneak peek of what to expect next:
- Simpler ingestion with robust validation.
- Faster Concurrent IO.
- The fastest streaming data loader for training models.
- Complete reproducible data lineage.
- External data source integrations.
So, What is the Future of AI?
1. Domain-Specific Complex Data Stored in AI-Native Format
Regardless if companies opt for general models like GPT-4, ‘small language models’ (smart enough smaller models), fine-tuning or RAG, or a mixture of both, they’ll need to organize and store their unstructured data in an AI-native format. Deep Lake was built from the ground up to be truly AI-native (tensor-based). This will help enterprises unlock more value from their multi-modal data and rapidly update their models for maximum accuracy (and revenue impact).
2. Production and Training Data Converging into Single Live Datasets
The distinction between data for training AI models and data used in production environments will blur. In the future, AI will continuously learn from live datasets, adjusting and improving in real time based on new information. This dynamic approach will drastically reduce the latency between learning and application, enabling AI systems to evolve at the pace of incoming data and ensuring that AI applications are always at the cutting edge of accuracy and relevance.
3. Compound AI Systems Morph Memory into Models
Like CPUs/GPUs with RAM on the Motherboard, memory and models are not distinct entities but seamlessly integrated. This architecture will significantly enhance processing efficiency and speed as the distance between data storage and computation is minimized. Such systems will be capable of more advance reasoning, faster learning, and more sophisticated interaction with the world, mirroring the cognitive processes of the human brain in their structure and functionality.
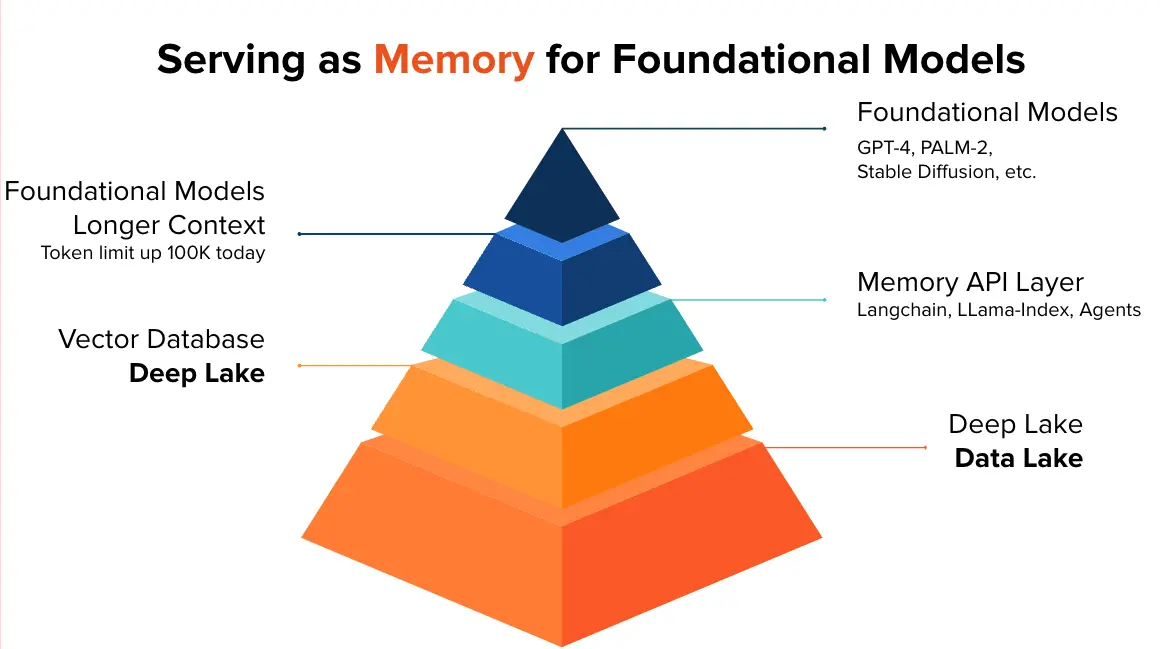
The future needs the Database for AI. So we are delivering it.
P.S. Our heartfelt thanks go to all of our supporters, partners, customers and open-source users that built the Database for AI with us. This milestone wouldn’t be possible to achieve without you!